 ai论文写作
ai论文写作
将偏倚数据视为AI辅助医疗中有启示性的伪迹
Considering Biased Data as Informative Artifacts in AI-Assisted Health Care
就像其他领域的人工智能(AI)工具一样,医学领域的AI工具也通过检测大量数据中的模式来发挥功能。AI工具可检测出这些模式是因为它们可以“学习”(或者说经过训练后,可以识别)数据中的某些特征。然而,采用某些方面偏斜的数据训练出的医学AI工具可能会表现出偏倚,而当偏倚与不公正模式同时出现时,这些工具可能导致不平等和歧视。对于训练AI时使用的有偏倚临床数据,试图修正这些数据的技术解决方案都是出于好意,但设计这些方案时所持有的想法是偏斜临床数据是“垃圾”,正如计算机科学领域一句很有名的话:“垃圾进,垃圾出”。而我们建议将临床数据视为伪迹,通过分析这些数据,它们可以提示产生这些数据的社会和制度状况。
通过将偏倚临床数据视为伪迹,可以发现医学和医疗领域存在不平等价值观、了解医疗实践和模式。将临床数据作为伪迹进行分析也可为当前医学AI开发方法提供替代方案。此外,通过将数据视为伪迹,可以将有偏倚AI的修正方法从狭隘技术视角扩展到社会技术视角,后者将历史和当前社会背景视为解决偏倚的关键因素。这种更广泛方法有助于实现公共卫生目标(理解群体不平等),也提供了应用AI的新方式(检测与健康医疗平等相关的人种和族群校正模式、缺失数据和群体不平等)。
我们正见证AI崛起。ChatGPT和DALLE等AI工具看似可以模仿人类智能,但它们实际上是计算机程序,可以对数据进行分类、归类、学习和过滤,从而解决问题、做出预测和执行其他看似智能的任务。就像其他领域的AI工具一样,医学领域的AI工具也通过检测大量数据中的模式来发挥功能。例如,使用大量有异常的影像对AI进行训练后,它可以学习检测医学影像中的异常。医学AI已展现出惊人能力,尤其是在影像学领域。在识别医学影像中的疾病方面,一些AI工具已经至少与经验丰富的影像科医师同样准确。
然而,如果训练医学AI工具时使用的是某些方面偏斜的数据,这些工具可能会表现出偏倚。例如,开发用于检测胸片中疾病的AI工具时,我们使用由成千上万张胸片(有疾病或无疾病)组成的数据集训练该工具。AI将从这些影像中学习识别疾病。然后,当展示新影像时,AI工具将能够确定胸片上是否有疾病证据。理想情况下,该工具将可以非常准确地识别疾病,而且用于每个人都是准确的。然而,如果训练数据包含大量具有特定特征(例如特定尺寸或形状的胸部,或者将影像标记为有病或无病的方式存在差异)影的像,则该工具将变得有偏倚。
上述例子源自现实。像其他AI应用程序一样,医学AI工具可能会因为训练数据中的已知和未知偏倚而变得有偏倚,而这种偏倚可能反映出社会不平等。最近一篇论文探讨了根据胸部影像,应用AI诊断疾病。该文章指出,即使采用包含成千上万张影像的数据集进行训练,AI模型也会在医疗资源匮乏人群和少数族群中出现漏诊。这种情况在同时符合两方面或多方面特征的群体(例如黑种人女性和西班牙语裔女性)中尤为明显。像这样的医学AI工具不仅有偏倚,而且也是造成健康医疗不平等的一个来源,因为在医疗资源匮乏人群和少数族群中已经存在不公平的健康医疗差距(图1)。例如,在美国,黑种人在肺癌早期得到诊断的可能性低于白种人。
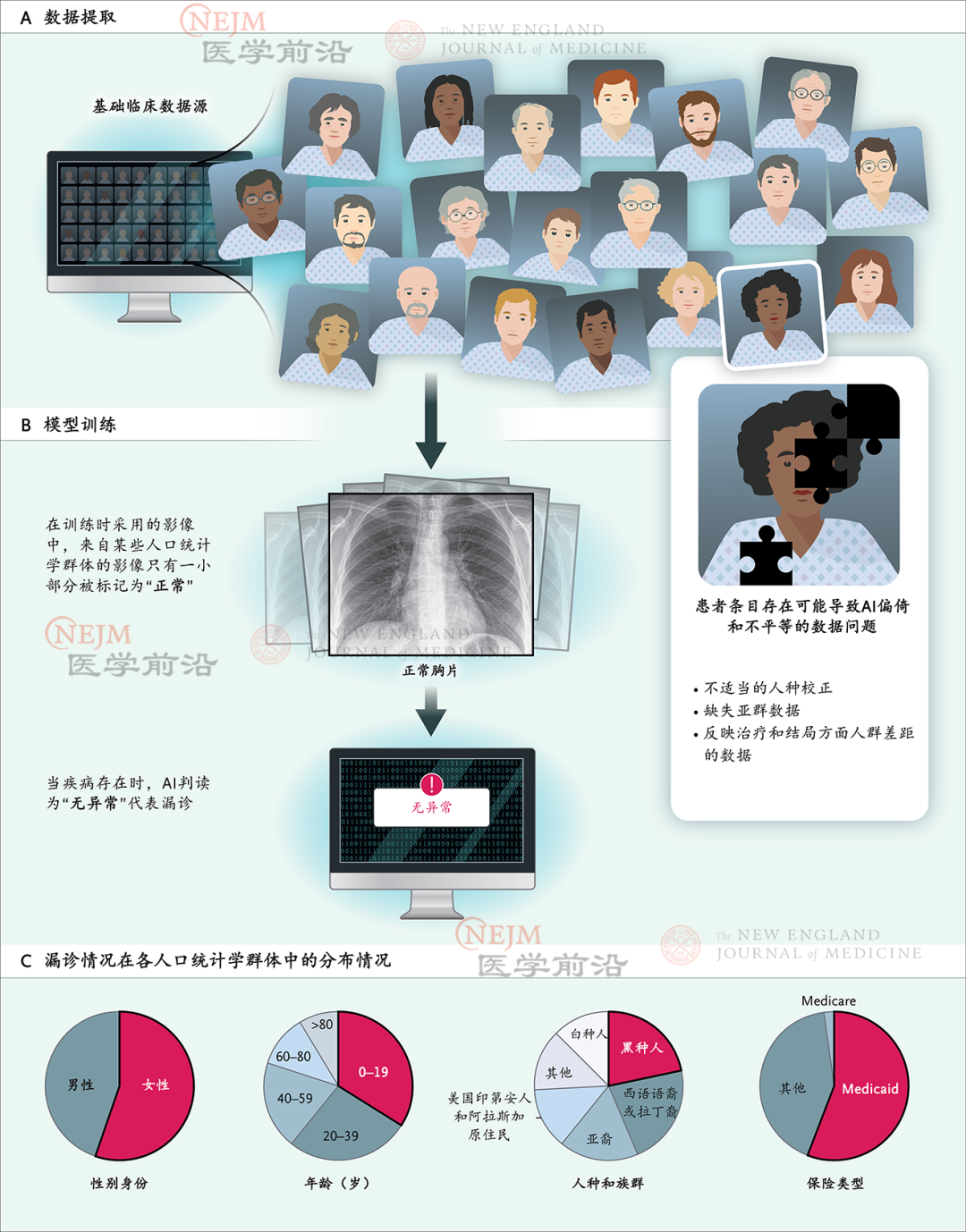
图1. 医学人工智能(AI)中的偏倚
在这个例子中,AI偏倚(也称为算法偏倚)很重要,因为它可能导致算法歧视。美国白宫科技政策办公室(White House Office of Science and Technology Policy)最近将算法歧视确定为其《人工智能权利法案蓝图》(Blueprint for an AI Bill of Rights)中的一个关键问题。科研和学术界也已认识到AI偏倚发展成算法歧视的潜力。
些人提出了技术解决方案,例如试图修正AI训练中使用的有偏倚临床数据。修正训练数据的一种方法是汇集或“联合”来自不同临床机构的数据,从而在其中包括人口统计学上有代表性的数据集。其他解决方案包括输入一些人口统计学类别的缺失数据或在不存在数据之处创建新合成数据,从而人为地构建人口统计学多样性。
人们也在努力为AI创建新的、多样化的、有代表性的数据集,方法是在数据集中包括广泛多样化人群,而不是人为地创建多样化数据或把不同数据集拼凑在一起。美国国立卫生研究院(National Institutes of Health)最近启动了Bridge2AI计划,该计划耗资9600万美元,旨在从头开始构建用于训练和建立新型医学AI工具的多样化数据集。
尽管这些努力都是出于好意,并且可以在最大限度减少AI偏倚和下游歧视方面取得一些进展,但设计这些措施时所持有的想法是偏斜临床数据是“垃圾”,正如前文提到的计算机科学领域一句很有名的话:“垃圾进,垃圾出”,意思是不良或错误数据会导致不良或错误分析结果。我们也认可偏斜或缺失数据会导致算法偏倚和歧视,但我们提出了另一种解决AI偏倚的方法。我们将这些数据视为伪迹。从考古学和历史学角度来看,伪迹是经检查后可提供社会相关信息(包括制度、活动和价值观)的事物。伪迹很重要,因为它们可以揭示早期社会的情况,即使它们揭示的信仰和做法可能与当代社会不一致。
通过类似方式,我们可以将训练AI时使用的临床数据视为伪迹,这些伪迹会揭示出可能令人不安的真相。例如,由Obermeyer及其同事开展,被广泛引用的关于医学中算法偏倚的研究表明,病情较重黑种人的医疗支出低于较健康白种人的医疗支出,这导致了不平等分配医疗资源的算法。然而,正如我们不会将显示危害的伪迹视为垃圾或应该修正的事物,我们也不应该忽视当前的临床伪迹。当被视为可以体现社会价值观的伪迹时,Obermeyer及其同事发现的有偏倚临床数据表明,正如社会学家Ruha Benjamin所写的那样,“黑种人患者并非‘花费更少’,而是被认为生命价值更低。”
因此,当偏斜临床数据被视为有启示性的伪迹,而不是垃圾时,我们可以利用AI中的模式识别能力帮助我们理解这些模式在历史和当代社会背景下的意义。下面三个例子说明了如何通过将偏倚临床数据视为伪迹,进而识别医疗中的价值观、医疗实践和不平等模式。将临床数据作为伪迹进行分析也可为当前的医学AI开发方法提供替代方案。
人们日益关注在临床数据中应用人种和族群校正因子。例如,2021年,慢性肾病流行病学合作研究(Chronic Kidney Disease Epidemiology Collaboration)报告了用于估算肾小球滤过率的新公式,这一新公式无需进行人种校正,而之前的公式需要根据推测的黑种人较高肌肉量做出“校正”。研究表明,医学中的人种校正可以追溯到使用男性白种人身体作为参考或标准,并以此衡量其他身体和生理功能的做法。
尽管遗传起源可提供一些临床相关信息,(如有助于预防疾病的遗传变异),但人们逐渐认识到,医学中的一些人种和族群校正有必要进行重新评估,因为其支持证据可能已经过时,使用这些校正可能会加重健康医疗不平等。
了解对临床数据进行人种校正的历史具有重要意义,因为临床预测模型可能建立在以下内在逻辑之上:人种和某些方面生理特征(如肺功能)之间存在由生物学决定的关系。这些数据和假设可被导入医学AI工具的开发中。如果不了解人种校正的历史,那么看似无形的偏倚(如经过人种“校正”的临床数据)可能很难通过纯技术手段修正。我们在此强调,种族主义价值观(如白种人属于正常或白种人至上)尽管在当代医学中已经被否定,但如果这些数据被用作训练集,它们仍可能影响当前医疗实践及未来医学AI工具开发。
由临床人员、患者、工程师或开发人员以及社会科学和人文学者组成的跨学科团队在上游将临床数据作为伪迹进行检查,可揭示出塑造数据的重要但隐含历史及其他因素。此类干预有助于识别将在下游导致歧视性AI工具的数据,并提出干预措施,用于解决造成这些偏斜数据的深层原因,如重新评估临床实践中的人种校正。
将偏斜健康医疗数据视为有必要仔细分析的伪迹也可指导医疗实践。对于数据和以数据为中心的工具(如AI)所存在的问题,这可以指明社会技术解决方案。例如,性别身份在临床数据中经常缺失。与其只考虑这些数据的修正方法或放弃目前已拥有的大量数据,我们可以分析这些数据所提供的丰富信息,并思考数据缺失提示了临床和社会实践中的哪些情况,例如临床用语中缺乏统一的生物性别和社会性别术语,以及医学信息采集表(medical intake form)仍在使用可能并非适用于所有人的过时性别身份术语。缺失数据可能还提示,一些人对披露该信息感到不自在或不赞成披露该信息,以及医务人员可能缺乏收集该信息的相关培训或不具备收集该信息的权力。
对健康医疗数据采取伪迹方法也推动了对于AI能力的新兴应用。因为AI可快速识别模式,所以它可以发现临床数据中的缺失,例如缺失特定人种群体,这可以作为生成假设的工具,进而推动关于临床医疗和健康医疗不平等的新的跨学科研究。如果我们将这些数据视为伪迹,我们就不再将AI中的偏倚看做可通过技术手段(例如输入缺失数据或创建新数据集)解决的问题。
将健康医疗数据视为伪迹而非垃圾也有助于揭示不同人群在医疗方面的不平等模式。遗憾的是,不公正健康医疗差距或健康医疗不平等的例子有许多,尤其是在美国少数族裔中。健康医疗数据反映了这些差距。如前文所述,黑种人患者确诊肺癌时处于较晚期阶段的可能性高于白种人。如果将这些数据用于训练癌症预测算法,数据中的这一偏倚可能会预测黑种人患者生存率较低。较低的预测生存率又会影响提供给这些患者的治疗选择,尤其是在偏向预期结局较好患者的医疗资源分配系统中。
对于这一有偏算法,纯技术应对方案是使用替代数据,或者在输入信息中排除确诊时的疾病阶段。然而,将这些数据视为伪迹有助于揭示不平等模式,这些模式凸显出诊断时的这些差异。这些数据的历史表明,直到2年前,肺癌筛查指南才做出修订,因为指南将高比例的黑种人归类为不符合早期癌症筛查标准。将健康医疗数据视为伪迹有助于阐明预防性医疗的人群层面排斥模式。如果不了解这段历史,数据将显示某一人群易出现不良医疗结局,而这种解读方式可能在新AI预测工具开发中成为其基础,这又会导致新的治疗不足和排斥情况(表1)。

AI和医疗界的偏倚日益受到关注,这是一个喜人现象,尤其是在COVID-19疫情仍有起伏的情况下。然而,AI的危害往往被不准确和狭隘地视为数据偏倚问题。尽管使用替代数据集的新型计算方法和让多样化参与者参与生物医学研究有意义,但这些不可能是唯一解决方案,它们也不应该基于过去和当前健康医疗数据对今天AI研发没什么帮助这一隐含观念。
我们建议从关注健康医疗数据缺陷转向将这些数据视为人类活动和价值观造成的伪迹。我们意识到,具有讽刺意味的是,考古学等领域的伪迹分析与殖民剥削的历史相关联。然而,我们借鉴了Zora Neale Hurston等人类学家的历史伪迹分析传统(他们旨在阐明被低估的历史和行为),以及当前学者的工作(他们认为,为实现算法公平,将档案方法[archival approach]作为替代方案非常重要),并将这些见解应用于医疗领域。
将医疗数据视为伪迹进行分析扩展了AI开发中数据偏倚的技术解决方案,提供了将历史和当前社会背景视为重要因素的社会技术解决方案。上述扩展方案有助于实现公共卫生目标(理解群体不平等),并提出了AI新用途(将其用于检测与健康医疗平等相关的数据模式)。我们认为应该改变视角,从而使医疗领域AI开发体现我们的承诺和责任:确保现在和未来的平等医疗。




版权信息
本文由《NEJM医学前沿》编辑部负责翻译、编写或约稿。对于源自NEJM集团旗下英文产品的翻译和编写文章,内容请以英文原版为准。中译全文以及所含图表等,由马萨诸塞州医学会NEJM集团独家授权。如需转载,请联系[email protected]。未经授权的翻译是侵权行为,版权方保留追究法律责任的权利。
点击下方名片,关注《NEJM医学前沿》






评论前必须登录!
立即登录 注册