 ai论文写作
ai论文写作生成式人工智能技术(简称“AIGC技术”)在文字处理、内容生成方面具有强大优势。
ChatGPT来源于GPT模型,通俗地理解为智能聊天机器人。它与先前的智能聊天机器人的最大区别在于能够通过学习、理解人类的语言,与人类进行对话,还能根据上下文语境进行理解、互动。
近年来,得益于神经网络、深度学习和生成模型等技术的快速发展,特别是预训练语言模型的出现,使机器具有了比较强的语义理解能力和长文本生成能力,AIGC技术也得到了迅速发展。
目前,AIGC技术在自然语言处理方面有明显优势,人们也在使用它进行写作。2023年初,美国电子书平台亚马逊刮起一阵“AI写作”风,人们向ChatGPT输入提示词就能完成几十页电子书的创作,并通过自助出版服务直接出售。截至2023年2月中旬,亚马逊Kindle商店已出现超过200本将ChatGPT列为作者或合著者的电子书。

人工智能进行文学写作的历史可以追溯到20世纪80年代。1983年,早期的人工智能文本生成器Racter诞生,它写作的《警察的胡子是半成品》被认为是第一部完全由计算机程序写作的文学作品。然而,这个阶段的AI文学写作主要依赖于预定义的规则和模板,生成的文本质量较低,在逻辑、可读性和创意方面都表现不佳。
进入21世纪后,随着深度学习与大数据技术的发展,AI写作进入了一个新的阶段,这期间诞生了如“微软小冰”“九歌”等AI写作平台,其中“小冰”已协助超过500万名用户写作现代诗歌,并出版了诗集,“九歌”已累计为用户写作超过700万首诗词。人工智能写作的运行逻辑,模仿的正是人类的写作以及写作教学行为。人工智能写作并非什么神秘的、与人类写作相对立的“他者”,而是人类写作活动被拆解后的重新具象化。
AIGC写作的优势在于能够根据用户的输入,快速生成语句通顺、表达合理的内容,给人一种“无所不知,无所不能”的印象。其实现的基本流程如图1所示。
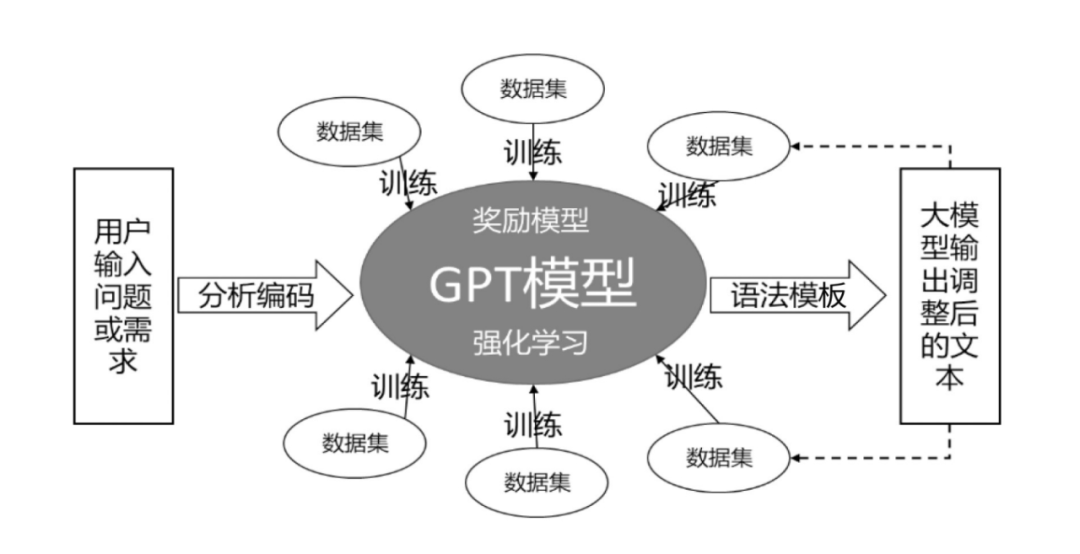
图1
首先,用户输入想要的问题或者需求,这些问题会被分析编码后进入一个比较复杂的GPT模型(GPT模型是由庞大的语料库,即数据集不断强化训练得到的)。
当编码后的问题经过一系列复杂运算后,GPT模型会将它认为“合适的回答”根据人类熟悉的语法习惯模板输出给用户,而且,这些问题和回答也都会成为新的数据集被GPT模型“记录”下来,持续训练,优化升级。接下来,我们来了解GPT模型、大语言模型、写作训练集等概念。
1.GPT模型
GPT模型是Generative Pre-trained Transformer的缩写,意思是基于Transformer生成式预训练模型。GPT模型能够根据输入的需要,生成一段让你看得懂的内容,是为ChatGPT等生成式人工智能技术提供支持的关键。GPT模型使应用程序能够创建类似人类的文本和内容(图像、音乐等),并以对话的方式回答问题。其中,Pre-trained意为“预先训练好的”。
一般来讲,在应用这种技术时,会需要先将大量的文本数据输入到模型中训练,让模型掌握语言的语法规则和表达方式,这个提前输入进行训练的过程被称为预训练。Transformer是Google的研究者在Attention Is All You Need一文中提出的概念,我们可以先将它简单理解为“转换器”。Transformer的基本原理是Encoder(编码)和Decoder(解码),也就是先将输入的内容转换为计算机能理解的内容,再将计算机理解的内容转换为人类能理解的内容。
2.大语言模型
大语言模型(Large Language Models,简称LLMs)是一类基于深度学习的人工智能模型。它们是由海量的数据和大量的计算资源训练而成的,通过无监督、半监督或自监督的方式,学习并掌握通用的语言知识和能力的深度神经网络。
LLMs的核心架构是Transformer,是一种由Vaswani等人于2017年提出的模型。Transformer的关键在于自注意力机制,这使得模型能够同时对输入的所有位置进行“关注”,从而更好地捕捉长距离的语义依赖关系。LLMs在Transformer的基础上进行了改进和扩展,通过在大规模文本数据上进行预训练,使得模型能够学习丰富的语言知识。
LLMs的训练过程分为两个阶段:预训练和微调。在预训练阶段,模型通过无监督学习在大规模文本数据上进行自我学习,从而具有一定程度的语言表示能力。在微调阶段,模型会在特定任务上使用有标签的数据进行有监督学习,以适应特定任务的要求。这两个阶段的组合使得LLMs在各种自然语言处理任务上表现出色。
3.写作数据集
以ChatGPT的训练数据集为例,它是由多个语料库组成,这些语料库包括各种类型的无监督文本数据,如网页、书籍、新闻文章等。这些数据既包括通用领域的文本,也包括特定领域的文本。ChatGPT的训练数据集主要有以下几个来源:
①BooksCorpus。这是一个包含11038本英文电子图书的语料库,共有74亿个单词。
②WebText。这是一个从互联网上抓取的大规模文本数据集。包括超过8万个网站的文本数据,共有13亿个单词。
③CommonCrawl。这是一个互联网上公开可用的数据集,包括数百亿个网页、网站和其他类型的文本数据。
④Wikipedia。这是一个由志愿者编辑的百科全书,包括各种领域的知识和信息,是一个非常有价值的语言资源。
除了以上几个来源之外,还有一些其他的数据来源为ChatGPT提供了大量的无监督文本数据,从而使得模型能够学习到各种类型和主题领域的语言知识。
有了数据源之后,接下来就要进行数据采样,以满足ChatGPT的训练要求。由于ChatGPT的预训练模型需要大量的无监督数据进行训练,而现实中可用的文本数据往往是非常庞大和复杂的,因此,需要采样来减少训练时间和计算资源的消耗,同时还需要保证训练数据的多样性、质量和平衡性,以提高模型的效果和泛化能力。
1.常用AIGC写作工具
①文心一言。文心一言是百度全新一代知识增强大语言模型,能够与人对话互动、回答问题、协助创作,具备更强的中文理解能力。
②WPS AI。WPS AI是金山办公旗下具备大语言模型能力的人工智能应用,为用户提供智能文档写作、阅读理解和问答等体验。
③星火。科大讯飞公司推出的认知大模型是以中文为核心的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务。
④Bing。Bing AI搭载了GPT4的Bing浏览器,它能够更好地理解用户意图,提供更加智能化、个性化的搜索和服务体验。
2.AIGC写作流程与使用建议
对AIGC写作而言,核心是训练一个能够生成连贯、语法正确、主题明确的长文本的神经网络模型。基本流程包括:
①数据准备。收集大规模的高质量文本数据,包括文章标题、内容、摘要等,并进行数据清洗、分词等预处理。
②模型选择。通常选择基于Transformer或LSTM等结构的预训练语言模型,这类模型在长文本生成任务上效果较好。
③模型训练。使用文本数据针对语言生成任务进行模型精调。训练目标是最大化生成文本的链式概率。
④文本生成。给定文章主题、关键词等条件,模型自动生成标题和正文。
⑤生成文本后处理。对模型生成文本进行语句规范化、语法纠错等后处理,提高可读性。
⑥结果评估。从语法、逻辑、连贯性等方面评估生成文本的质量,并反馈改进模型。
AIGC技术关键是利用大规模预训练模型,让模型学习各类文章语言的语法和风格特征。相比以往基于模板的方法,预训练模型生成的文本连贯性更好,接近人工写作的效果。当然,目前仍需人工审核,以确保生成质量。
使用AIGC技术帮助写作,关键问题是要学会如何提问,如何让AIGC工具懂得你的问题,理解你的需求,这样它才能给你满意的回答。这里推荐一个提问的框架——由温州大学方建文博士人工智能教育研究团队设计的RTGR框架,该框架具体包括角色(Role)、任务(Task)、目标(Goal)、需求(Requirement)四个要素。
例如,要让AIGC设计一份班会课方案,输入提示语:如果你是一名高中班主任,请制作一份关于学生“防范网络诈骗”的班会课方案,举例和分析当下中学生发生过的网络诈骗案例,帮助学生认识常见的网络诈骗手段,能够采取有效防范措施,方案字数1000字以内,内容尽量详细,条理清晰。使用RTGR框架分析这段提示语,如图2所示。
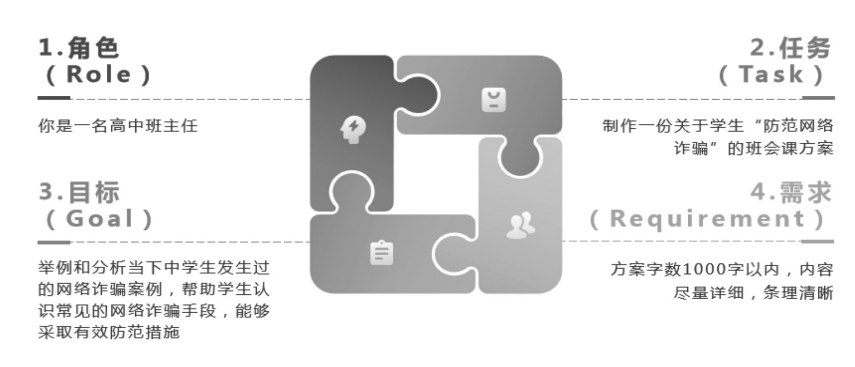
图2
3.AIGC辅助写作举例
以百度文心一言为例,举例介绍如何使用AIGC技术辅助写作。
(1)文章选题
确定文章选题是写作的第一步,如果你只是知道文章的大致方向和角度,还不清楚如何确定更加细致的选题,可以考虑使用AIGC帮你推荐选题。文心一言实现设计文章选题的核心原理是深度学习技术,特别是自然语言处理(NLP)的相关算法和模型。通过语义理解、知识图谱、文本生成以及机器学习算法等技术手段精准地解析用户意图,关联背景知识,并生成符合用户需求的文章选题。同时,大数据分析技术的应用进一步提升了选题的准确性和用户满意度。这些技术的综合应用使得文心一言能够高效地为用户提供有价值的文章选题建议。
(2)写作框架
有了选题后,还需要确定写作框架,才能使文章“有迹可循”,更有逻辑。可以考虑由AIGC来补充写作框架,进一步打开思路。文心一言首先解析用户输入,识别写作意图,然后规划包括主要观点、分论点和逻辑关系的文章框架,最后生成具体内容并反馈给用户。在这一过程中,预训练语言模型、知识图谱等技术提供了语法、语义和背景知识的支持,确保生成的框架结构清晰、内容丰富,符合用户需求。
(3)文献梳理
在写作特别是撰写学术文章的时候,往往要对研究对象做文献梳理,传统的方法是一篇一篇去阅读记录,最后梳理汇总成文。现在可以考虑使用AIGC技术帮助我们记录学习的文献并进行梳理汇总。需要注意的是,要完成这项工作光靠一条提示语是不够的,还需要通过多次输入来“教会”文心一言。
例如,要做有关“中小学人工智能课程教学情况”的文献梳理工作,可以在文心一言中多次输入提示语来实现。
提示语1:我正在撰写有关人工智能课程教学的期刊论文,现在打算进行文献综述部分的写作。目前我已经准备了5篇来自核心期刊的文献作为文献综述的对象。请针对所有文献展开分析,并提炼如研究问题、研究角度、研究方法、研究结论等要素。接下来,我将分多次将文献摘要的信息发送给你,请你完成学习,并在每次收到后只要回复三个字“已学习”即可,最后我会请你帮助汇总成表格。你清楚了吗?
提示语2~6:依次复制5篇论文的标题、作者、摘要。
提示语7:请针对所有文献展开结构要素分析,并提炼如研究问题、研究角度、研究方法、研究结论等要素,每个要素为一列,第一列是论文编号,以表格的形式输出。
提示语8:请根据目前学习的文献摘要和梳理的表格内容,对当下中小学人工智能课程开设情况进行文献综述梳理,在引用相关文章时,尽量加上第一位作者的姓名,字数500字左右,要求逻辑清晰、语句通顺。
(4)概念释义
在写作过程中,经常会遇到一些不太清楚的概念,或者是语句扩写,或者是想要更加全面地了解某个名词,可以考虑使用文心一言进行查询。在这一过程中,自然语言处理帮助系统深度理解话题和文献内容,机器学习提升信息提取和撰写的准确性,而信息检索则确保快速找到相关文献。例如,输入提示语“什么是人工智能,用200字介绍”,可以得到有关人工智能的一些介绍内容,对有些不清楚的地方还能继续追问。
(5)语句优化
人们在写作时有时会存在内容口语化、重复化,或者句子结构不合理、有语病等情况,AIGC技术能够快速梳理结构,使语篇规整。文心一言运用分词、词性标注、句法分析、语义理解等一系列技术,通过接收、预处理、理解分析用户输入的文本,并基于Transformer架构捕捉语义信息,生成更加通顺精练的表达建议,从而有效优化文本质量。例如,输入一段话并提示语要求优化文字表达,就能够提炼原文的内容,使其更加精练。
(6)绘制图表
文心一言基于数据可视化原理,通过数据解析、图形映射和视觉呈现等关键技术,将用户数据高效转换为直观图形,并利用前端交互设计提升用户体验,从而实现数据的快速理解和分析。例如,选择“E言意图”插件功能,输入提示语要求生成本校师生的人数饼图,分析计算后就能够得到一张彩色的饼图。
(7)图表分析
AIGC技术具备将报表或流程图转换成文字连贯表达出来的能力。文心一言的“说图解画”功能在让用户上传图片后,利用计算机视觉技术识别图片内容,再通过自然语言处理技术生成易懂的解释,其核心技术在于图像的智能识别和自然语言的自动生成,以实现图片的快速解读和信息传递。例如,选择“说图解画”插件功能,先上传一张图片,输入提示语“要求写一篇关于人工智能、机器学习和深度学习三者关系的文章”,就能够得到想要的结果。
(8)生成摘要
化繁为简考验全文概览,提炼总结的能力。AIGC可以从成千上万的文章中提取几百字的摘要。文心一言的“览卷文档”功能让用户在上传文档后,通过深度解析文档内容,识别主题和关键信息,进而自动生成简洁准确的摘要,帮助用户快速把握文档核心。例如,选择“览卷文档”插件功能,先上传一篇论文文档,系统通过解析文档内容就可以得到这篇文章的摘要。
除了上述方法,百度文库还推出了文档助手的功能,当在文库中打开某篇文档查阅资料时,可以随时在文档助手中提问。例如,提问:“该文档主要内容是什么?”“写一下阅读这篇文档的读后感。”这种方式节省了时间,提高了效率,也使用了AIGC技术。
1.数据局限问题
从目前来看,GPT4数据集缺乏多语言、多文化视角。OpenAI发布的数据显示,在训练ChatGPT所使用的数据集中,大约96%为英文内容,其余包括中文在内的20个语种加起来不足4%。既然GPT4的数据集以英文为主,我们就不难推断,其数据背后所容纳的思想、文化、经验、生活同样以英文世界为主。
当前,已有学者表示ChatGPT“在尊重除了美国的其他国家的文化背景和使用习惯上仍有欠缺”,同时也有学者对GP3.5进行中文性能评测,发现其中文知识和常识储备不足,在中文闭卷问答上出现事实性错误的概率较高。
另外,目前GPT4仅能处理25000字左右的文本,这意味着GPT4的“记忆力”仅为25000字,当字数超过25000字时,GPT4将会逐步遗忘讨论的内容。还有,目前GPT4训练数据截至2021年,这意味着如果作者需要以2021年以后的人物或事件为素材进行写作,或者要查询相关资料,GPT4能提供的帮助有限。
2.伦理法律问题
本文作者:
文章刊登于《中国信息技术教育》2024年第05期
引用请注明参考文献:
倪俊杰.拥抱并克制,合理使用AIGC技术辅助写作.[J].中国信息技术教育,2024(05):76-81.

欢迎订阅
点击图片即可订阅





评论前必须登录!
立即登录 注册