 ai论文写作
ai论文写作2022-11-16
使用maskR-CNN人工智能模型生成集成物料清单
Generating integrated bill of materials using mask R-CNN artificial intelligence model
作者:
Ayesha Munira Chowdhury(Department of Civil & Environmental Engineering, Pusan National University, Busan 46241, South Korea)
Sungwoo Moon(Department of Civil & Environmental Engineering, Pusan National University, Busan 46241, South Korea)
期刊:Automation in Construction
原文连接:https://doi.org/10.1016/j.autcon.2022.104644
Q1
文章提出的工程问题是什么?
有什么实际工程价值?
混凝土模板是一种临时结构,在施工期间用作混凝土浇筑模具。通常,混凝土模板占据了混凝土预算的很大一部分,需要正确的数量估算和成本估算。模板成本占施工项目总预算的15%,占混凝土结构总预算的33%。数量估算和成本估算的错误计算可能导致时间延误和成本超支。因此,应规划和管理好混凝土模板。
本文的目的是将人工智能与成本数据库集成,以自动生成模板BOM表。提出了一种BoM生成AI模型(BoM GAIM),该模型可以基于掩码R-CNN和光学字符识别(OCR)技术自动生成BoM。所提出的模型使用2D CAD模板图纸的图像进行训练,可以从2D CAD图纸图像中识别、分类和提取模板组件。遮罩R-CNN片段用像素位置来模板组件以及标注对象。随后,OCR将标注对象转换为数字信息。然后,该AI模型根据分段构件的数量确定混凝土模板构件数量,并最终与成本数据库结合估计混凝土模板总成本。
Q2
文章提出的科学问题是什么?
有什么新的学术贡献?
混凝土模板是混凝土浇筑的关键临时结构,不仅在结构设计中,而且在预算规划中。传统的规划管理主要采用人工的手段,但人工智能(AI)在规划和管理这一临时结构方面具有巨大潜力,可以自动计算数量和估算成本。
本文的目的是将人工智能与成本数据库集成,以自动生成模板材料清单(BoM)。提出了一种基于掩码R-CNN和图像分割技术的BoM生成AI模型(BoM-GAIM)。所提出的模型使用2D CAD模板图纸的图像进行训练,可以识别、分类和提取模板组件。发现训练后的掩码R-CNN的平均平均精度(mAP)在交集对联合(IoU)=50%时为98%,在IoU=75%时为85%。光学字符识别(OCR)也用于从尺寸对象中提取数字信息。最后,结合成本数据库,BoM GAIM在用户界面环境中生成了混凝土模板的BoM。BoM GAIM的应用简化了BoM生成,提高了混凝土模板设计效率。
Q3
文章提出的技术路线是什么?
有什么改进创新之处?
技术路线:
本文介绍了BoM GAIM,一种自动生成混凝土模板BoM的模型。通过使用2D模板绘制图像来提取模板组件(如护套、托梁、支柱和管道支架),使用Mask R-CNN技术对模型进行训练,以进行对象识别和分割。BoM GAIM是使用集成AI模型训练和成本数据库的整体方法开发的,以自动生成混凝土模板BoM。
1.基于maskR-CNN的目标识别与分割
对象识别和分割是确定每个对象的对象标签和分割掩码的过程[16]。maskR-CNN[17]对于实例分割非常流行[18]。maskR-CNN类似于Faster R-CNN[19],只是它有一个额外的分支,用于以像素到像素的方式预测每个感兴趣区域(RoI)上的分割掩码。Mask R-CNN架构分两个阶段工作。第一阶段,区域提案网络(RPN)提交目标对象(即RoI)的边界框,与Faster R-CNN的相同。在第二阶段,RoIAlign为每个RoI提供二进制掩码。作为参考,Faster R-CNN使用RoIPool提取目标对象的特征,并最终预测对象类。
maskR-CNN已用于许多最近的建筑工程研究。Wang等人[20]使用了两级策略,即结合Faster R-CNN和Mask R-CNN来检测历史釉面砖的损伤形态特征,如损伤拓扑、面积和比率。Ying和Lee[21]提出使用maskR-CNN来自动识别和分割具有随机形状的建筑对象,同时根据建筑图像构建原样BIM对象。Kim和Cho[22]使用Mask R-CNN检测不同类型的混凝土损伤,如裂缝、风化、钢筋暴露和剥落。Li等人[23]使用直方图阈值maskR-CNN绘制新旧建筑的地图。
本研究使用Mask R-CNN从2D模板绘制图像中提取模板组件,并执行对象识别和分割。图1展示了maskR-CNN结构以及2D CAD图纸上的对象识别和分割过程。残差网络101(ResNet101)模型从目标图像提取特征。特征金字塔网络(FPN)具有在多个尺度上表示特征的能力,可以与ResNet101模型相结合,以提高maskR-CNN的速度和精度[17]。
图1:maskR-CNN执行图像分割
当2D模板绘制图像被馈送到Mask R-CNN过程时,ResNet101和FPN模型的组合提取RoI特征[17]。然后,RPN生成区域建议,这些区域建议是图像中可能存在RoI的可能区域。接下来,RoIAlign围绕RoI生成特征图,并最终提供三个输出:对象类、边界框和对象遮罩。
RoIAlign是Mask R-CNN结构中的独特特征,它提供了感兴趣对象周围的二进制掩码。最后,maskR-CNN使用完全卷积网络(FCN)预测每个RoI的掩码。更快的R-CNN使用RoIPool代替RoIAlign,这无法提供输入和输出之间的像素对像素对齐[17]。因此,与Faster R-CNN不同,Mask R-CNN可以实现对象遮罩,在Faster R-CNN中,只接收带有类标签的边界框。对象遮罩获得所需图像块的精确位置。maskR-CNN可以计算2D模板绘制图像中感兴趣的对象的数量。
2.整体进场程序
BoM GAIM采用整体方法将人工智能能力与混凝土模板估算成本数据库相结合。图2显示了用于开发BoM GAIM的程序,该程序分为两部分:1)模型训练和开发,2)集成BoM生成。首先,模型训练和开发部分包括步骤1-3。步骤1在2D模板CAD图纸的图像上训练Mask R-CNN模型;步骤2通过训练的模型馈送目标模板图像(要为其生成BoM);并且步骤3生成具有检测到的、分类的和定位的感兴趣对象的训练的掩码R-CNN模型输出图像。
其次,集成的BoM生成部分包括步骤4-7。这里,步骤4将包含模板组件的数字规格的图像块与生成的掩模分离,因为掩模R-CNN在感兴趣的对象周围创建二进制掩模,步骤5应用光学字符识别(OCR)系统。在OCR的帮助下,读取BoM所需的信息(即组件的长度/宽度)。此外,还根据为特定模板组件生成的遮罩数量收集其他信息,如组件数量。步骤6创建成本数据库,并以用户界面方式将其与BoM GAIM集成,其中根据用户从成本数据库中选择的选项为每个模板组件生成BoM。最后,步骤7将四个组件的总成本或BoM汇总为最终输出。

图2:整体方法的七个步骤
创新之处:
1.应用Mask R-CNN的图像分割技术从二维模板图纸中提取模板构件。
2.通过将 BoM-GAIM 与成本数据库集成,对用户界面系统进行了原型设计,并可以成功生成具体的模板物料清单。
Q4
文章是如何验证和解决问题的?
一、模型培训和开发
BoM GAIM首先使用通过对象标签获取的对象掩码进行模型训练。一组2D模板绘制图像用于训练AI模型。使用新的2D模板绘制图像数据集测试训练的掩码R-CNN,以显示对象识别和检测中的模型可预测性。
在训练阶段,利用预训练的Mask R-CNN模型和转移学习。转移学习方法冻结ResNet101+FPN+RPN+RoIAlign层,并使用新数据集重新训练掩码R-CNN的FCN层[24]。本节讨论了模型训练过程以及Mask R-CNN模型的测试结果。
1.3D CAD图纸准备
图3(a)显示了从东南方向看混凝土模板板的3D CAD图。共绘制了93张3D CAD图纸,其中包含不同尺寸的混凝土模板组件,用于具有不同水平和垂直间距的护套、托梁、支柱和管道支架。在数据集中,护套的长度在3000和9000毫米之间,宽度在2000和4000毫米之间;托梁的间距在910和980mm之间;支柱的间距在400和480mm之间。管道支架放置在托梁和支柱的横截面上。
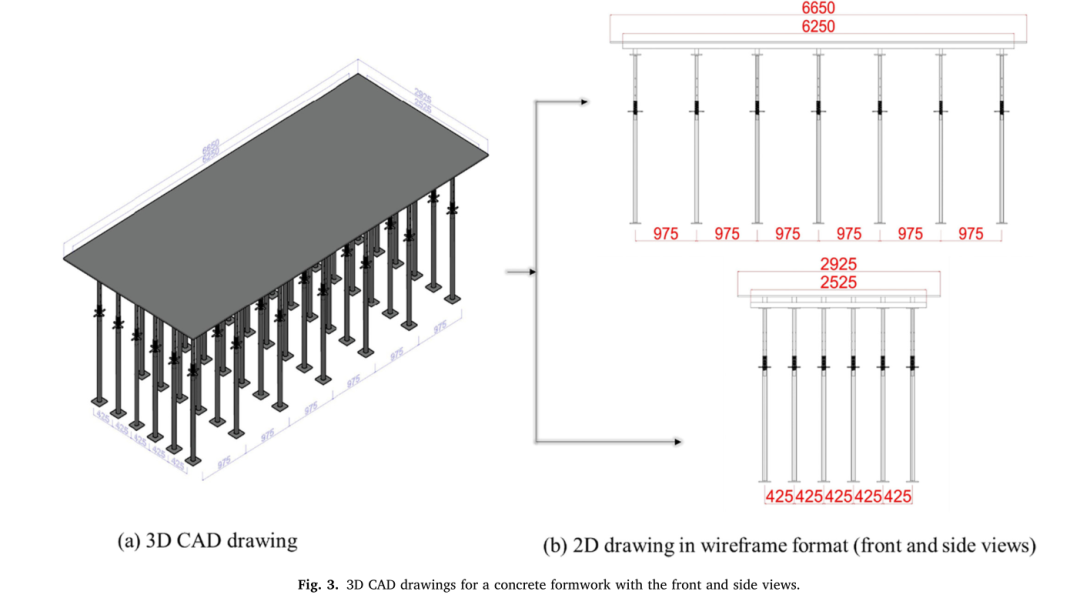
图3:混凝土模板的3D CAD图纸,包括前视图和侧视图
然后,以2D线框格式从这些3D CAD图纸中收集2D前视图和侧视图图纸(图3(b))。使用Python PyPDF和pdf2图像库将这些2D图形转换为.jpeg格式。因此,在前视图和侧视图中总共准备了186张2D混凝土模板图像,用于Mask R-CNN训练。
2.图像标签和数据收集
在数据收集之后,需要进行一些后处理来执行CNN训练,尤其是当涉及到对象分割时。标记是图像分割后处理的一项基本任务。术语标签是指为图像中的特定对象分配标签或特定名称的任务[25]。在这项研究中,所有186幅图像中的每个模板组件都被手动标记。在此过程中,模板模型以AutoCAD 2D线框格式从AutoCAD保存,用于BoM GAIM培训。
标签程序在Labelbox(一个用于图像注释的在线平台)上执行。图4显示了Labelbox上的标签过程示例。围绕管道支撑创建多边形对象遮罩,围绕护套、托梁、支柱和尺寸创建矩形对象遮罩。标记过程在2D模板绘制图像中提供感兴趣对象的边界。标记的数据以JSON文件格式接收。这个JSON文件帮助为每个标记的图像创建对象掩码和XML文件。对于每个标记的图像,将为图形图像中的对象创建单独的遮罩图像。
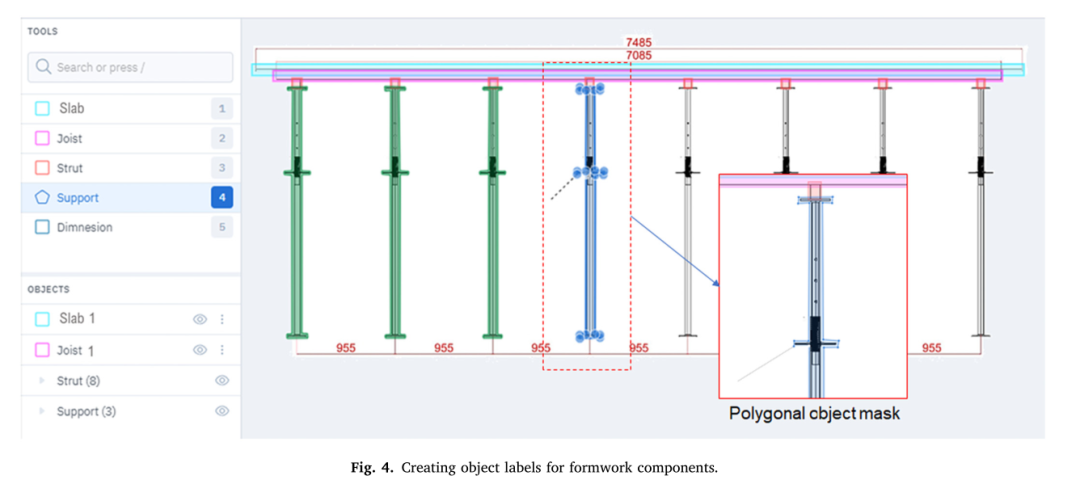
图4:为模板构件创建对象标签
图5显示了在Labelbox中完成标记工作后模板组件的对象遮罩以及尺寸对象。在图中,已在模板的侧视图上进行了手动对象分割。这里对象掩码是0和1的二进制图像,其中0表示背景像素,1表示对象像素。对象遮罩包括护套、托梁、管道支撑、支柱和尺寸的遮罩。总共为186张训练图像创建了3353个标签,因此总共生成了3353张对象遮罩。
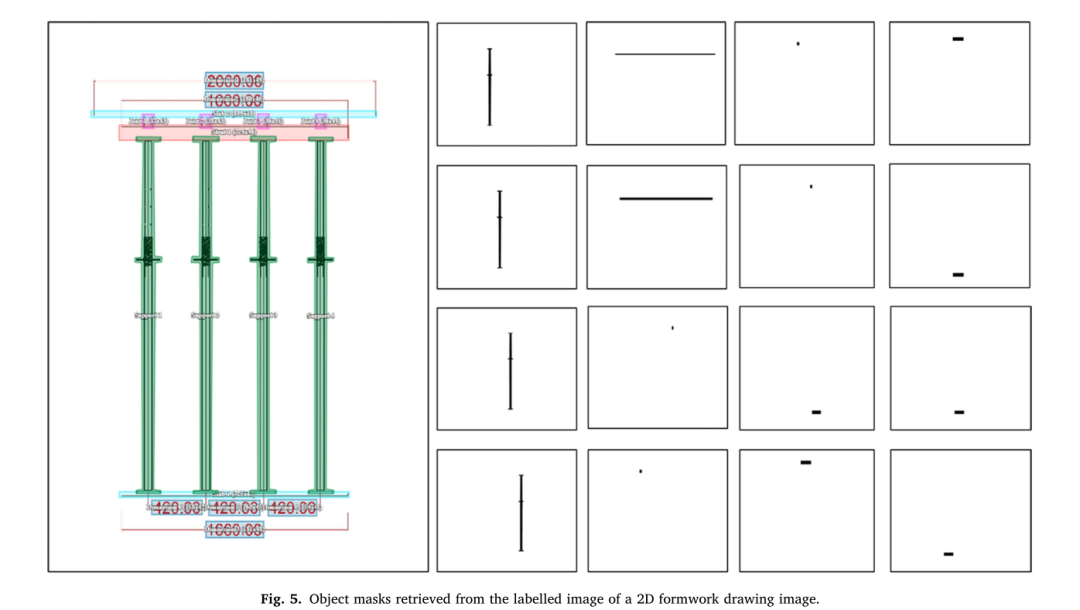
图5:从2D模板绘图图像的标记图像中检索的对象遮罩
与对象掩码的位置(即坐标)相关的信息存储在XML文件中。尽管为每个对象遮罩创建了一个单独的遮罩图像,但每个图像都有一个XML文件,其中存储了关于一个模板绘图图像中所有对象遮罩的位置/坐标的所有信息。最后,TFRecord存储所有RGB图像、PNG掩码图像和XML文件中的数据以及创建图像列表和类列表。TFRecord是用于存储TensorFlow对象检测API[26]数据的标准格式,可以帮助存储用于训练BoM GAIM的所有信息。
3.对象定位和提取
平板混凝土模板由四个部分组成:1)护套、2)托梁、3)支柱和4)管道支架。护套通常由胶合板制成并承载混凝土荷载,托梁支撑护套,支柱将荷载从托梁传递至管道支架,管道支架将荷载传递至地面[27]。典型的二维板模板图纸包含具有数字尺寸的护板、托梁、支柱和管道支架。为了方便起见,在本研究的标签过程中,护套仅被称为平板,这就是为什么在图4中护套被标记为“平板”而不是“护套”的原因。
BoM GAIM分两个阶段从2D CAD图纸生成BoM:1)物理对象提取和2)数值数据提取。阶段1通过对象定位、分割和分类从2D模板绘图图像中提取混凝土模板组件,而阶段2从Mask R-CNN模型的分割掩模中提取数字信息,可用于集成BoM生成。
①物理对象提取
经过训练的掩码R-CNN可以检测、定位和分类二维CAD绘图图像中的对象。然而,全面的Mask R-CNN模型需要时间和资源进行训练。在这种情况下,可以应用转移学习技术,这在训练Mask R-CNN模型中花费更少的时间和资源。该技术将特征提取知识从源域转移到目标域[28]。当应用转移学习时,ResNet101+FPN+RPN+RoIAlign层中的参数从预训练的Mask R-CNN加载,并且根据2D模板绘制图像的数据集微调Mask R-CNN的FCN层的参数。
最初,Mask R-CNN是在名为Microsoft Common Objects in Context(MS COCO)的标记数据集上训练的[29]。COCO数据集包含80个对象类别的328K图像,用于各种目的(对象检测、分割、关键点检测、字幕等)。当加载预训练的掩码R-CNN时,ResNet101+FPN层中的参数从先前的训练中加载到MS COCO数据集[30]。
物理对象提取主要使用TensorFlow API和其他多个Python库。当2D模板绘制图像被提供给训练的Mask R-CNN模型时,物理对象提取1)检测每个组件,2)在每个模板组件周围创建分割掩模,3)预测模板组件的标签或类别(图6)。
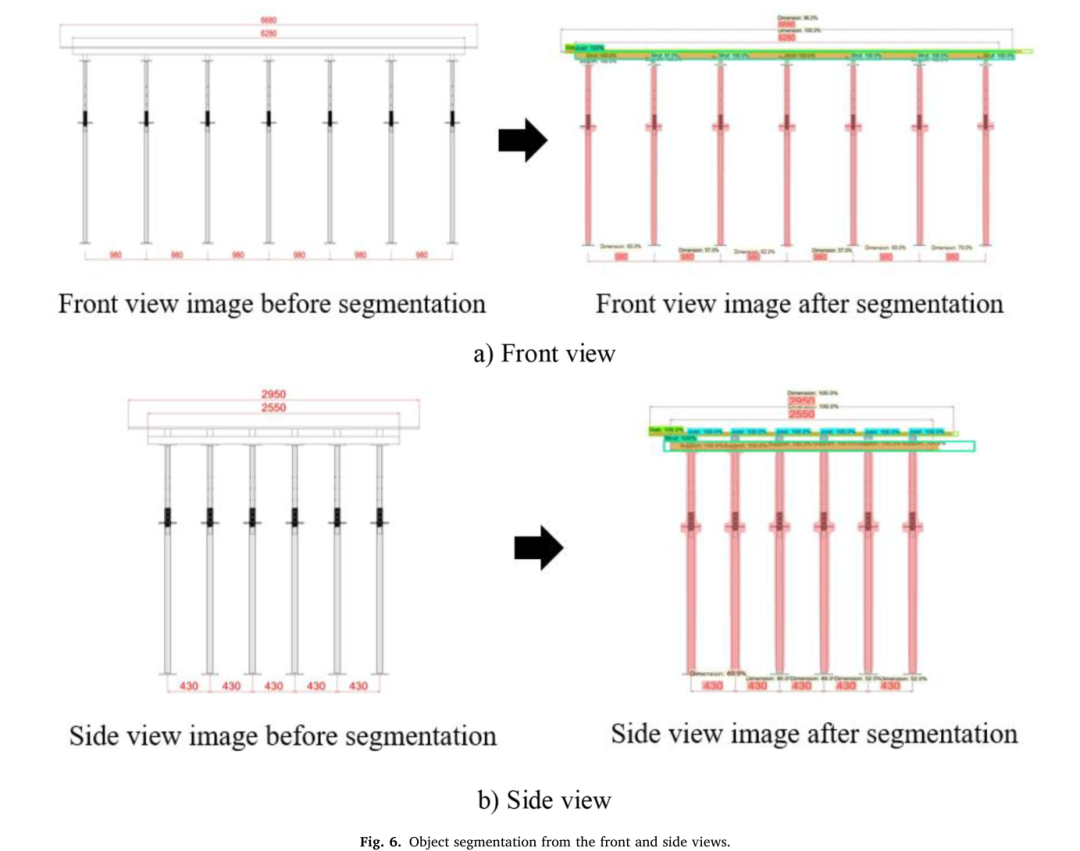
图6:从正面和侧面视图进行对象分割
②数值数据提取
在物理对象提取阶段,包括尺寸在内的模板组件被本地化。此外,另一方面,数值数据提取阶段基本上处理BoM生成的信息提取。该阶段包括根据掩码R-CNN创建的每个组件的分割掩码的数量,从两个输入2D模板绘图图像中计算每种类型的模板组件(即护套、托梁、支柱和管道支架)的数量。
由于BoM GAIM作为集成BoM生成的原型模型,数值数据提取基于以下假设:
·BoM GAIM用户可以根据管道支架的横截面积、高度、材料等选择类型。
·BoM GAIM用户可以根据横截面积、材料等选择托梁/支柱的类型。
对于混凝土模板的BoM生成如下,必须在数字数据提取阶段找到信息:
•前视图:护套长度、托梁长度、支柱数量、支架数量
•侧视图:护套宽度、托梁数量、支柱长度、支架数量
数值数据提取阶段分为三个步骤:
步骤1计算分割的2D模板绘图图像(图7)的模板组件的数量。在“物理对象提取”区域中,遮罩R-CNN已分割模板组件对象。在本节中,将计算对象遮罩的数量以计算模板组件的数量。在这项研究中,用python编写了定制程序代码,以确定模板组件、托梁、支柱和管道支架的数量。
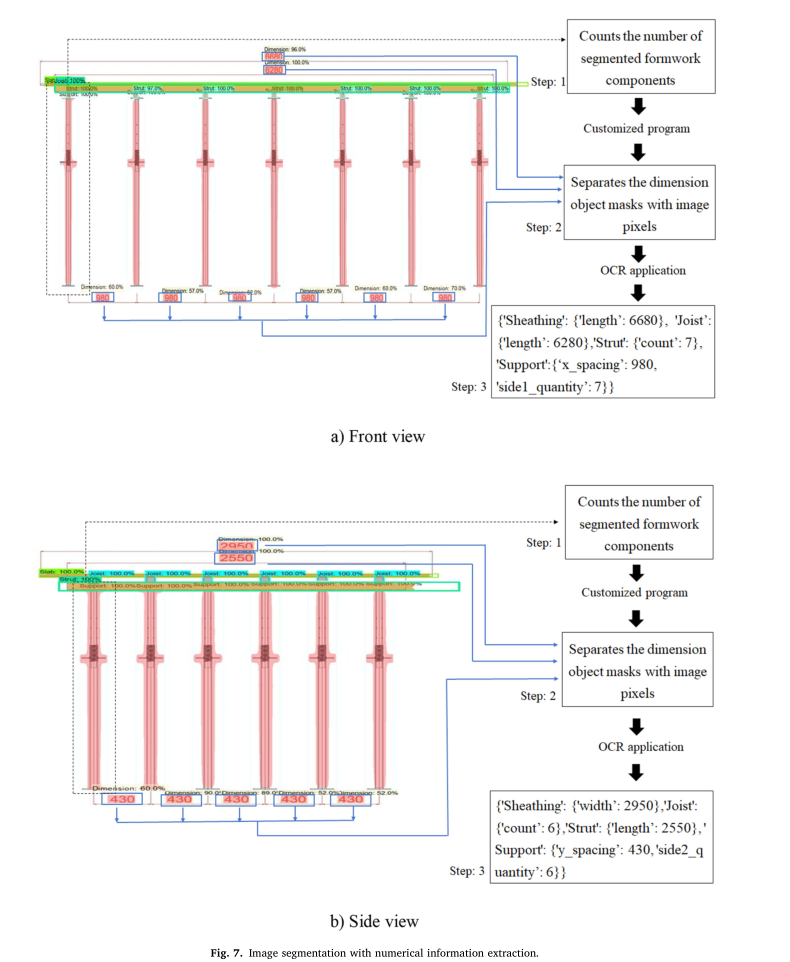
图7:基于数字信息提取的图像分割
步骤2将对象像素位置分配给在前一物理对象提取阶段生成的维度掩码(图7)。然后,应用光学字符识别(OCR)技术提取数字信息。这里,OCR是一种将机器打印或手写的文本2D图像转换为机器可读文本的系统。OCR使用对象像素位置来了解尺寸遮罩在2D模板绘图图像中的位置。当OCR从尺寸掩模中提取数字信息时,应分离精确的对象像素位置,以确保正确的结果。
OCR技术常用于建筑工程。Sajadfar等人[31]在文本提取中应用OCR边界框对施工文件进行分类。Kim等人[32]提出了一种字符识别技术,作为传统识别技术(如用于建筑材料管理的RFID条形码)的替代方案。Python tesseract或pytesseract是谷歌tesseract OCR或OCR的Python包装器[33]。它可以读取Python Pillow库支持的任何图像格式。Pillow是Python图像库(PIL),用于打开、读取和保存图像[34]。
在物理对象提取阶段,Python Pillow库用于读取输入的2D模板绘制图像,并使用训练的Mask R-CNN模型分割每个组件。然后,在数值数据提取阶段,首先分离维度像素,然后使用Python库Pytesseract读取模板组件的数值。
步骤3基于从步骤1接收到的信息生成两个Python字典。字典包括模板组件信息,如护套的长度/宽度、托梁/支柱的长度和托梁/支杆的数量(计数)。
例如,在图7(a)中,6680和6280分别表示护套和托梁的长度,单位为mm,而7表示支柱的数量。对于支架,x_spacing和side1_quantity指的是图7(a)前视图中的间距(980 mm)和支架数量(7)。类似地,在图7(b)中,2950表示护套的宽度,单位为mm,而2550表示支柱的长度,单位为毫米;6表示托梁的数量,而y_spacing(430 mm)和side2_quantity(6)表示侧视图中支撑的间距和数量。应注意,管道支架的间距也代表托梁和支柱的间距。
4.Mask R-CNN 训练
在本地计算机系统(CPU:Intel(R)Core(TM)[email protected],RAM:48.0 GB,GPU:NVIDIA GeForce GTX 1660)上使用TensorFlow对象检测API的培训平台执行培训。Python版本为3.6,TensorFlow版本为1.15。
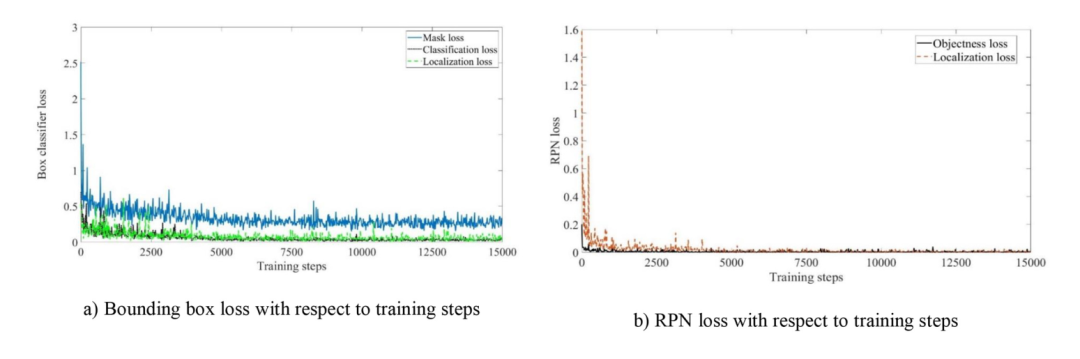
数据集被转换为训练子集(70%)和验证子集(30%)的两个不同的TFRecord文件。模板图纸为pdf格式,随后通过Python代码直接转换为图像文件(.jpeg格式)。未对这些2D模板绘图图像进行裁剪。模板绘制图像具有1920×1040像素的高分辨率。Mask R-CNN以0.003的基本学习率(0.9的动量)和0.0005的权重衰减训练5000次和10000次迭代。培训持续了15000步。由于图像分辨率很高,需要5天时间完成15000步的训练。(maskR-CNN是Faster R-CNN模型的扩展,训练模型的超参数根据Faster R-CNN模型进行调整)
训练损失是解释深度学习模型的训练性能的一种方式,损失值越高表示预测与实际值偏差过大,反之亦然。掩码RCNN在每个采样RoI上的多任务损失函数是分类、定位和分段掩码损失的组合:L=Lcls+Lbox+Lmask。
Girshick等人[35]将前两个损失解释为Fast R-CNN工作中的分类损失和边界盒损失。每个训练RoI都标记有地面实况类x和地面实况边界框回归目标y。
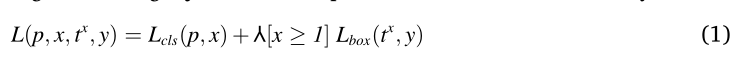
其中Lcls(p,x)=−logpx是真实类x的对数损失,p表示(n+1)个类别或类标签上的离散概率分布。概率分布p由softmax层计算。
另一方面,Lbox表示类x的真实边界框回归目标元组y(y=(yx,yy,yw,yh))和预测元组tx(t=(tx,ty,tw,th))。这里,x,y,w和h分别表示x坐标、y坐标、宽度或水平长度以及高度或垂直长度。功能⅄ [x≥ 1] 当x为1时≥ 1表示目标,否则0表示背景。数学上,
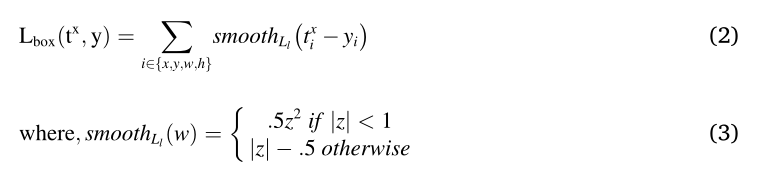
Girshick等人[35]提到,Ll是一种稳健损失,对异常值不太敏感。对于每个RoI,掩码分支接收np2维输出,对于n个类中的每一个,编码分辨率为p×p的n个二进制掩码。最后,Lmask被计算为RoI上所有像素的平均二进制交叉熵损失。
图8(a)显示了盒分类器的分类、定位和掩码损失,而图8(b)显示了RPN的定位和对象性损失。对象性损失是指如果边界框是感兴趣的对象或背景,则对其进行分类的分类器的损失。当所有损失接近0或几乎为0时,在箱式分类器的掩模损失的情况下,在15000步结束时损失非常接近0。较低的损失值表明训练做得很好,模型学习得很好。图8(c)显示了总损失。到训练结束时,损失曲线减少了17倍,这意味着模型在这段时间学会了很好的预测。
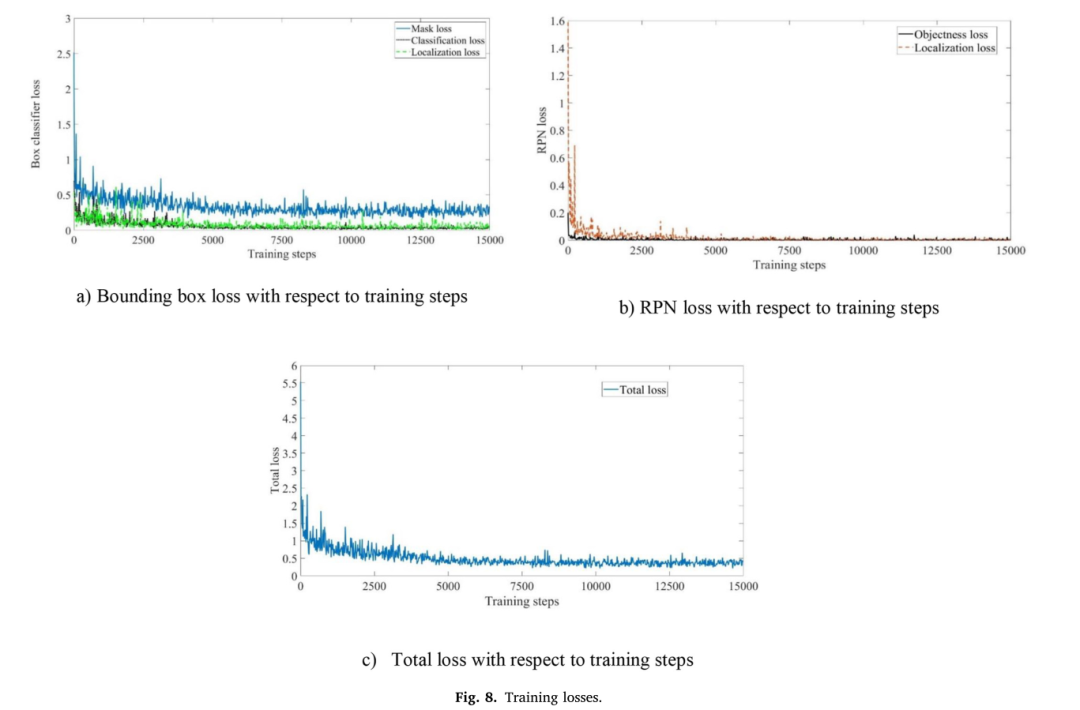
图8:Training losses
5.模型验证
训练完成后,使用30%验证子集对训练模型进行评估。该模型通过交叉口超联合(IoU)阈值处的平均精度(mAP)进行评估。IoU表示预测RoI和地面真实数据之间的IoU阈值。因此,IoU评估两个边界框之间的重叠:地面真实数据边界框和预测边界框。

另一方面,精度测量预测的准确性,

这里,TP表示真阳性的数量,而FP表示假阳性的数量。
表1表示两个不同IoU阈值(0.50和0.75)下验证子集上的mAP。当IoU=0.50时,mAP为98%,当IoU增加至0.75时,mAP下降至85%。IoU是评估对象检测和分割模型的有力手段。然而,Pan等人[36]提到,当较小的IoU被应用时,预测的RoI和地面真实数据之间的重叠区域也很小。尽管在这种情况下,预测仍然假设为正,但这可能会导致不适当的结果。因此,使用的最佳IoU阈值通常在0.50到0.75[36]之间。
表1:平均精度
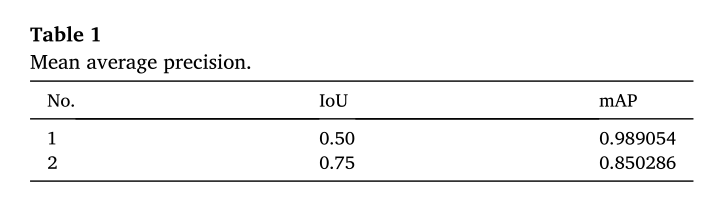
这项研究还使用了两个阈值:IoU=0.50和IoU=0.75。AP值是所有类别的平均值,因此它们实际上代表了mAP。mAP值越大,精度越高,当mAP值高于0.5时,任何检测都被视为真阳性[37]。表1显示,当IoU=0.50时,mAP为98%,当IuU=0.75时,mAP为85%。正如Pan等人[36]所述,IoU越小,mAP越高。这就是为什么当IoU=0.75时mAP会下降的原因。尽管当IoU=0.75时mAP值下降到85%,但两个mAP值都显著高于50%,因此模型学习良好。
最后,分别绘制了10张混凝土模板的3D CAD图纸,以测试经过训练的BoM GAIM。在BoM GAIM培训中,以2D线框格式收集了20张2D前视图和侧视图图纸。测试数据集与护套、托梁、支柱和管道支架的训练数据集在同一范围内编制。在测试中,BoM GAIM能够准确地为所有20幅模板绘图图像提供类标签、边界框和分割掩码。
这些分割图像中每个检测到的类标签旁边的数字(如图9所示)表示置信度得分,或训练模型正确检测到对象的可能性,以百分比值提供[38]。图9显示了分割后的两个测试图像,包括对象标签、边界框、分割掩码和相应的置信度分数。大多数感兴趣对象的置信度得分接近90%;然而,在一些轻微的病例中,得分也较低,如60%。
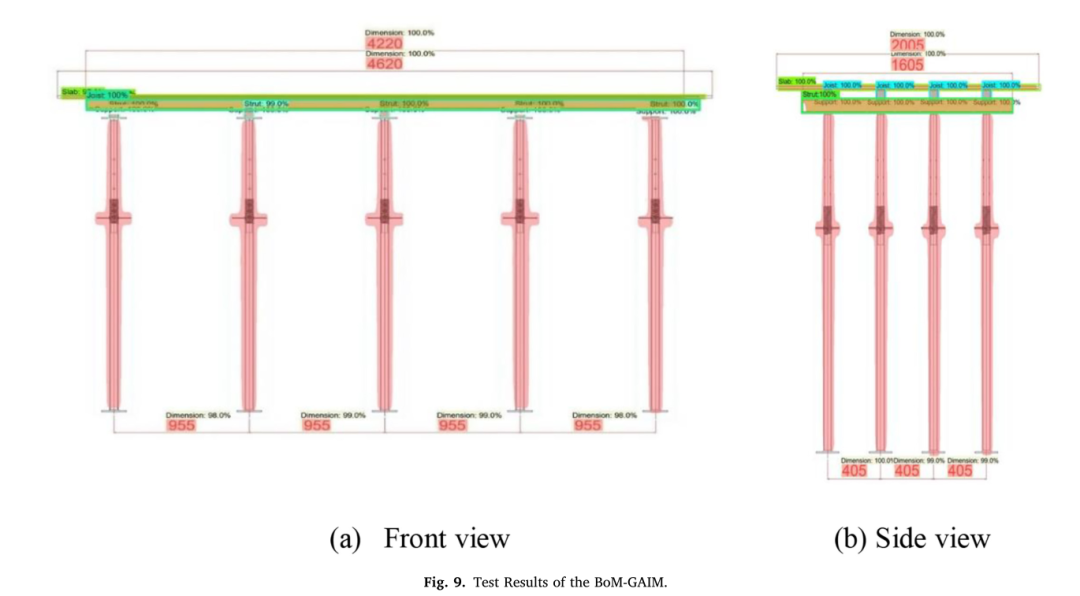
图9:BoM GAIM测试结果
二、集成BoM生成
本节介绍了一个示例应用程序,展示了BoM-GAIM如何生成混凝土模板BoM。BoM GAIM使用在数值数据提取阶段生成的定量数据进行综合BoM生成。这种自动化使得能够将来自数字数据提取阶段的定量数据与成本数据库集成。由于目前建筑行业通常使用成本数据库,BoM GAIM可以通过人工智能和数字成本数据库的集成来实现。
1.示例应用程序
作为案例研究,执行了一个示例应用程序,以演示如何在实践中实现BoM GAIM。首先,BoM-GAIM从正面和侧面为一块简单的板拍摄了两张2D模板图。板厚20厘米,长6000毫米,宽2500毫米。该图纸是一张实际施工施工图,经过简化后适用于BoM GAIM。进行此简化是为了删除不必要的图形信息。该图被放入BoM GAIM中用于对象识别和分割。
图10显示了物体分割前后的前视图和侧视图以及生成的Python字典。原始模板图像被用作BoM GAIM的输入数据,该GAIM生成带有对象遮罩的模板图像。这里,目标模板图像以特定格式命名,用于精确定量数据生成。如对象定位和提取部分所述,第一阶段是物理对象提取,其中BoM GAIM首先使用训练的掩码R-CNN执行分割任务。第二阶段是数值数据提取,从两个视图的两个图像生成两个Python字典。
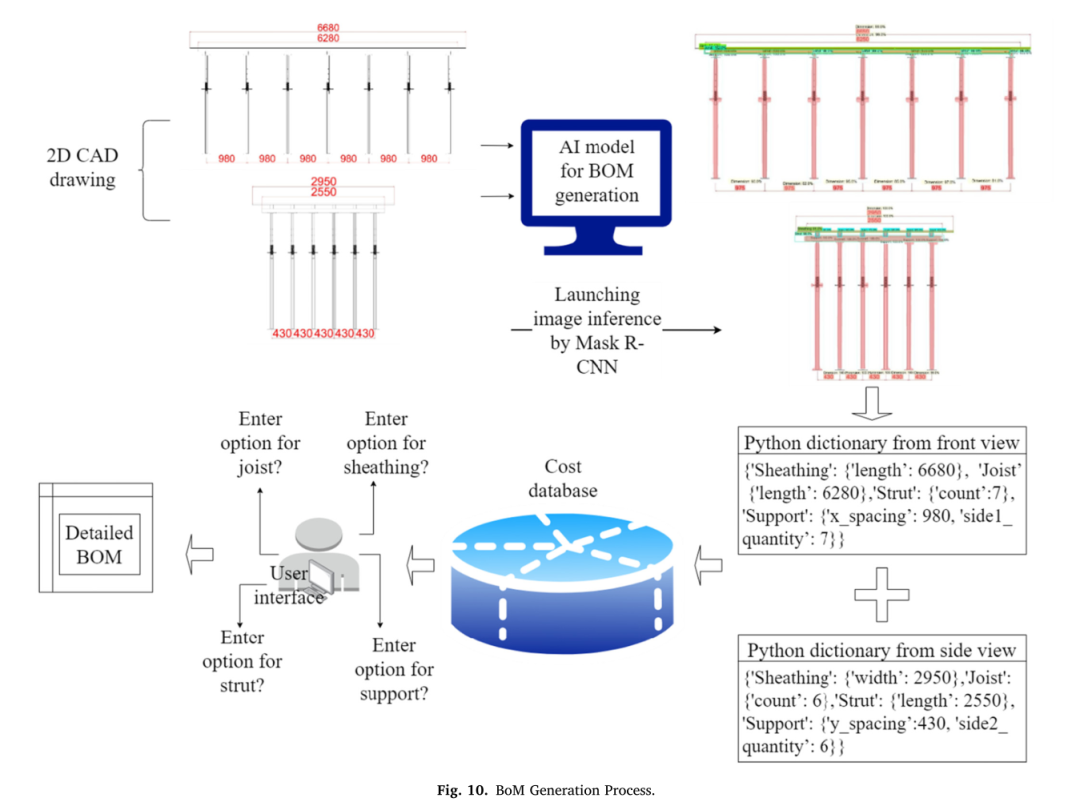
图10:BoM生成流程
下一步是在BoM GAIM中集成成本数据库和用户界面。为了使工程量清单生成过程自动化,集成成本数据库是一个关键步骤,用户可以在该数据库中选择自己喜欢的模板组件。成本数据库为用户提供了根据建设项目需求、周围环境条件和项目预算选择组件类型的便利。
BoM GAIM从两个视图中分割两个模板图像并相应地创建Python字典大约需要1分钟。如果模板组件的数量减少,则处理时间将减少,反之亦然。根据模板组件选择活动,用户界面可能需要任意时间。仅BoM GAIM就需要大约30-40秒来生成与成本数据库接口的总BoM。由于可以在几分钟内完成全部BoM生成,因此承包商可以审查各种选项以提高设计效率。
2.成本数据库设置
成本数据库以表格格式存储不同条件和规格下每个组件的价格。假设考虑到管道支架内的所有零件(u形头、千斤顶底座、螺母、螺栓等),每个管道支架的成本总计。对于护板、托梁和支柱,材料供应商提供特定尺寸的混凝土模板组件,因此,价格根据尺寸规格而有所不同。
BoM GAIM根据成本数据库中的单价计算每个组件的价格。通常,成本数据表被组织为包含项目、单位、数量、费率等列。在本研究中,成本数据库格式被修改为与Mask R-CNN集成。当每单位成本可用时,模板工程量清单可按如下方式生成(成本(美元)):
·护套:(长度×宽度(m2))×成本($/m2)×护套面板数量(ea)。
·托梁:{(长度(m))×单位长度成本($/m)}×托梁数量(ea)。
·支柱:{(长度(m))×单位长度成本($/m)}×支柱数量(ea)。
·管道支架:单位部件成本(u形头、千斤顶底座、螺母、螺栓等成捆)($/ea)}×管道支架数量(ea)。
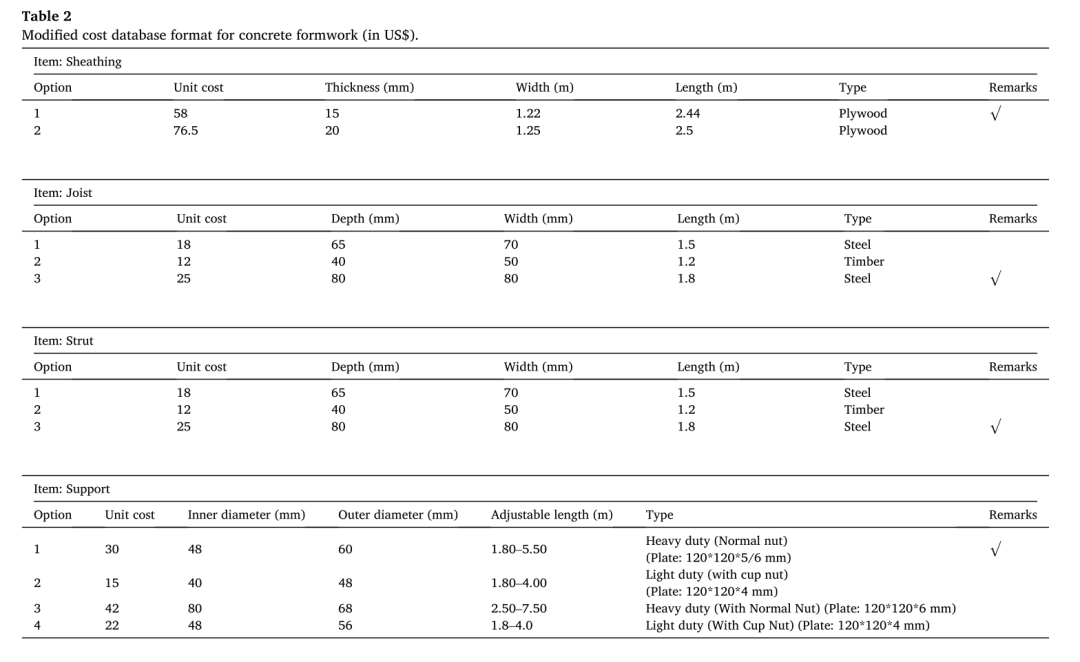
在Microsoft Excel中创建的成本数据库根据宽度、长度和厚度(或单位)以及不同条件列出了所有模板组件及其定价信息。例如,对于护套,价格将根据面板的横截面而变化。也就是说,1.22×2.44米护套板的价格与1.25×2.5米护套板不同。同样,横截面积为40×40 mm、长度为1.8 m的托梁或支柱的价格与横截面积65×70 mm、长度1.5 m的托梁和支柱的价格不同。每个组件的定价信息存储在单独的表格中。因此,对于四个模板组件,应存放四张单独的板材。
随后,在数字数据提取阶段,Python编码与CNN集成,在CNN中,Pandas Pythons库用于读取Excel文件中的表格。当模型初始化时,在模板组件的图像分割和字典生成之后,BoM GAIM用户会被问及首选选项。例如,对于护套,选项1是1.22×2.44平方米的面板,其市场价格为50美元,而选项2是1.25×2.5平方米的板,市场价格为60美元。如果用户输入选项1,价格将根据该特定价格计算。
表2显示了模板零部件数据库的格式。该表描述了与BoM GAIM一起使用的成本数据库。该表包含每个项目的价格、尺寸、单价和类型信息(即护套、托梁、支柱和支撑)。这个表只是表示数据库的格式,而不是整个数据库。最后,根据所选选项,在数值数据提取阶段还提供了每个模板组件的数量。此外,在数值数据提取阶段,还提供了管道支架之间的间距,这与前视图中托梁和侧视图中支柱的间距相同(图10)。因此,该阶段还可以帮助设计师/工程师或承包商在检查工作中检查2D模板图纸图像是否符合图纸规范。
表2:修改后的混凝土模板成本数据库格式(美元)
3.自动生成BoM
目标图像应包含前视图的扩展名“-f”和侧视图的扩展号“-l”。当启动BoM GAIM时,首先,Mask R-CNN在模板绘图图像中分割模板组件,然后,应用OCR技术提取数字数据。当数字数据可用且图像扩展名为“-f”时,BoM GAIM将最大值指定为护套长度。例如,在图。护套长度为106680mm。之后,BoM GAIM将第二大数字指定为托梁长度。例如,6280 mm是托梁长度。BoM GAIM将最小的编号指定为管道支架之间的间距(以及支柱之间的间距)。例如,980 mm是管道支架的间距长度。
随后,BoM GAIM从2D模板图纸图像中的分段管道支架的数量中计算支架的数量,并以Python字典的形式组合这些信息。类似地,为模板绘图图像的侧视图创建了另一个Python字典。然后,BoM GAIM拥有生成总BoM所需的所有信息。接下来,BoM GAIM用户界面将BoM GAIM与成本数据库集成(图11)。在此阶段,要求用户从成本数据库中输入首选选项。根据输入的选项和两个Python字典中的数字尺寸,BoM GAIM首先为每个项目提供BoM,最后为总BoM。

图11:用于选择成本选项的BoM GAIM用户界面
表3显示了每个模板组件(第六列)产生的BoM和总成本。200×6000×2500-mm3的板临时结构需要7块1.22×2.44mm2的胶合板、21块80×80×1800-mm3的托梁、10块80×180×1800-m3的支柱和42个重型管支架,条件是托梁间距或管支架间距在前视图中为980mm,支柱间距或管架间距在侧视图中为430mm。
表3:综合BoM发电的最终产量(成本单位:美元)
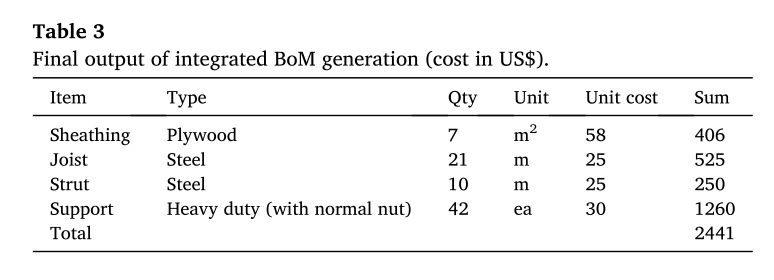
在这里,BoM GAIM用户可以在准备2D图纸时选择管道支架和托梁/支柱的间距。如果间距增加,模板的数量和预算成本也会增加,反之亦然。对于护套,七块1.22×2.44 m、18 mm厚的胶合板的成本为406美元。对于21块尺寸为80 mm×80 mm×1.8 m的托梁,成本估计为525美元,对于10块尺寸相同的支柱,成本估计是250美元。
最后,42个带普通螺母的重型管道支架的施工成本估计为1260美元。BIM框架中模板总成本2441美元。随后,计算出的工程量清单与实际账单进行了验证,发现由于测试期间建筑市场的价格波动,工程量清单略有不同。此外,预测数量与具体选择的选项的实际数量完全匹配。
Q5
文章有什么可取和不足之处?
逻辑结构:本文的outline呈现在下文:
1. Introduction
阐述了混凝土模板在工程中的重要性以及对其进行科学规划的必要性。
2. Overview of BoM-GAIM
2.1 Object recognition and segmentation using mask R-CNN
使用mask R-CNN进行识别和分割。
2.2 Holistic approach procedure
BoM GAIM采用整体方法将人工智能能力与混凝土模板估算成本数据库相结合。
3. Model training and development
3.1 3D CAD drawing preparation
在前视图和侧视图中总共准备了186张2D混凝土模板图像,用于Mask R-CNN训练。
3.2 Image labelling and data collection
在这项研究中,所有186幅图像中的每个模板组件都被手动标记。在此过程中,模板模型以AutoCAD 2D线框格式从AutoCAD保存,用于BoM GAIM培训。
3.3 Object localization and extraction
实验室混凝土模板主要识别四个部分:1)护套、2)托梁、3)支柱和4)管道支架。
3.4 Mask R-CNN training
介绍了训练的相关配置。
4. Integrated BoM generation
4.1 Sample application
作为案例研究,执行了一个示例应用程序,以演示如何在实践中实现BoM GAIM。
4.2 Cost database setup
成本数据库以表格格式存储不同条件和规格下每个组件的价格。
4.3 Automated BoM generation
介绍了BoM目标图像的生成过程。
5. Conclusion
本研究将BoM GAIM作为一种新的方法,将AI与成本数据库相结合,用于自动生成混凝土模板BoM。BoM GAIM自动从2D模板绘图图像中提取模板组件对象,包括数字尺寸。掩码R-CNN技术用于对象识别和提取。OCR技术用于量化这些对象的信息,以用于自动生成BoM。根据模板组件的市场价格创建了成本数据库。然后,BoM GAIM生成了与成本数据库集成的模板BoM。
从上述内容可以看出,本文主要采用理论-实验的逻辑结构,文章整体上逻辑清晰,排布合理。
研究方法:
1.在数据集的标定上,本文的设计可以更具体一点,尽管只有100多张图像,但实际上一张图像中有多个可识别信息,因此可以考虑全面的描述数据集,这样可以充分展示自己的数据容量,也使文章更有说服力。
2.本文的一个亮点是在案例研究中,专门设计了一个应用程序来实施实验,对于复杂的系统而言,这种集成式的方式可以进一步提高研究的价值。
图表形式:
这里的loss曲线可以考虑将刻度再拉大一点或者调整一下色度,原图的效果中多个曲线重合在一起,遮挡现象严重,不易看出曲线间的的差异情况。
文字表达:
这里在于IoU阈值的描述中最好是采用统一的描述方式,即小数制和百分制选一种即可。


Q6
文章对自身的研究有什么启发?
本文主要运用深度学习方法和数据库方法相结合,实现了自动生成混凝土模板BoM。
由于是结合的方法,整个流程的步骤十分复杂,因此在本文中,在进行案例分析时作者特地制作了一个示例应用程序,对于复杂的系统而言,这种集成式的方式可以进一步提高研究的价值,值得借鉴!
长按识别二维码关注
撰写:鲁亚楠
排版:鲁亚楠
审核:李浩然





评论前必须登录!
立即登录 注册