 ai论文写作
ai论文写作撰稿 | 王蕴泽
责编 | 刘 坚 连晨


研究背景
在肿瘤学中,患者状态的特征包括各种模态,如放射学、组织病理学、基因组学到电子健康记录,具体如图一所示。然而目前的人工智能模型主要在单一模态的领域内运作,忽视了更广泛的临床背景,这不可避免地降低了它们的潜力。不同数据模态的集成为提高诊断和预后模型的鲁棒性和准确性提供了机会,使人工智能更接近临床实践。人工智能模型还能够发现解释患者预后或治疗耐药性差异的模态内和跨模态的新模式。从这些模型中收集到的见解可以指导探索研究,并有助于发现新的生物标志物和治疗靶点。
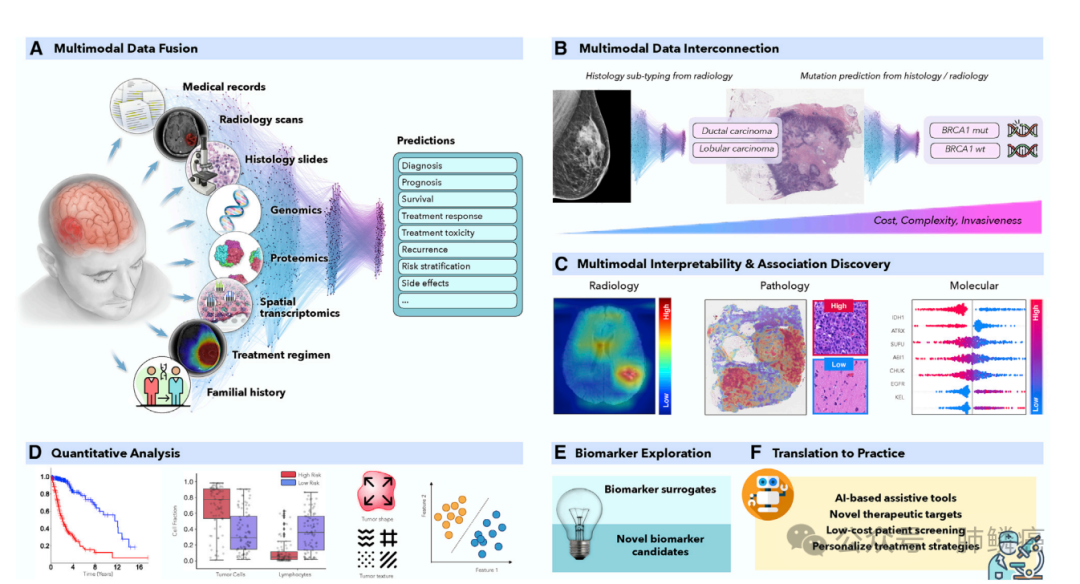
图一:AI驱动
研究结果
一、肿瘤学中的常用的人工智能方法
1.监督学习方法
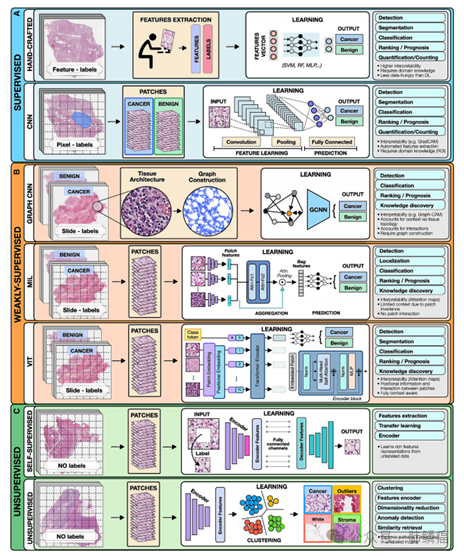
B)表示学习方法
在深度学习方法中,如卷积神经网络(CNNs),模型能够从原始数据中学习丰富的特征表示,而无需进行手动特征工程。CNNs通常用于图像分析,其架构包括交替的卷积、池化和非线性激活层,以及少量的完全连接层。卷积层用于特征提取,池化层用于压缩特征表示,非线性激活函数允许模型探索复杂的特征之间的关系。CNN的优势包括能够从原始数据中提取丰富的特征表示,减少预处理成本,提高灵活性,并通常优于手工制作的模型。然而,CNN的局限性包括对像素级注释的依赖,可能受到评估者之间的变异性和人类偏见的影响,以及对一些临床结果的预测区域可能是未知的。CNN也常常因缺乏可解释性而受到批评,但尽管有这些限制,它们在许多临床相关应用中表现出令人印象深刻的性能,得到广泛应用。
2.弱监督学习方法
A)图卷积网络
图形可用于捕获数据结构并编码对象之间的关系,是分析组织生物医学图像的理想选择。图由连接的节点和边组成,节点可以代表细胞、图像补丁或组织区域。边编码节点之间的空间关系和交互作用。这些图可以与患者水平的标签结合,由图卷积网络(GCN)处理,类似于在非结构化图上操作的CNN的泛化。在GCN中,节点的特征表示通过聚合相邻节点的信息来更新,并作为最终分类器的输入。与传统的数字病理深度模型相比,GCNs可以包含更大的背景和空间组织结构,将图像补丁分解为相互交错的小区域,适用于超出单个补丁范围的空间上下文任务(例如,Gleason分数)。然而,GCN中节点之间的相互依赖性增加了训练成本和内存需求,因为这些节点不能独立处理。
B)多实例学习(MIL)
MIL是一种弱监督学习,输入的多个实例没有单独标记,监督信号仅适用于一组通常作为袋提供的实例袋的标签,假设为阳性,如果袋中至少有一个阳性实例。模型的目标是预测包的标签。MIL模型包括三个主要模块:特征学习或提取、聚合和预测。第一个模块用于将图像或其他高维数据嵌入到低维嵌入中,该模块可以进行动态训练或预先训练,来自监督或自监督学习的编码器可用于减少训练时间和数据效率。实例级嵌入被聚合以创建患者级表示,并作为最终分类模块的输入。一个常用的攻击策略是基于注意力的池化,其中使用两个完全连接的网络来学习每个实例的相对重要性。由相应的注意力评分加权的补丁水平的表示被总结,以建立患者水平的表示。注意力分数也可以用于理解模型的预测基础。在大规模的医疗数据集中,通常没有精细的注释,这使得MIL成为训练深度模型的理想方法,在癌症病理学和基因组学中已有几个最近的应用。
C)Vision Transformer(VITs)
VITs是一种注意力机制学习类型,与MIL相比,VITs考虑了补丁之间的相关性和上下文。其主要组成部分包括位置编码、自我注意和多头自我注意。通过将WSI转换为带有位置信息的补丁,并使用可学习的编码器映射到标记化的向量中,VIT体系结构实现了幻灯片级表示用于分类。变压器编码器由堆叠的相同块组成,包括多头自我注意和MLP,以及层归一化和残差连接。尽管VIT具有合并空间信息、增加上下文和鲁棒性的优点,但通常对数据需求较高。弱监督方法可以降低数据预处理成本、减轻偏差和评估者之间的可变性,并且适用于大型数据集、不同任务和未知预测区域。这些方法能够自动识别出预测特征,甚至超出了病理学家通常评估的区域,证明了在没有昂贵手工注释或特征工程的情况下实现了良好的性能。
3.无监督学习方法
多模态数据融合旨在提取和整合不同模态之间的互补上下文信息,以促进更好的决策。在医学上,这一方法尤为重要,因为同一发现在一个模态中可能有不同的解释。例如,单独使用IDH1突变状态或组织学特征可能无法充分解释患者预后的差异,因此将它们结合起来已被用于重新定义WHO弥漫性胶质瘤的分类。人工智能提供了一种自动化和客观的方法,可以整合来自不同数据的互补信息和临床背景,从而改进预测。多模态数据驱动的人工智能模型还能够利用不同模态中的补充信息,以增强预测的鲁棒性和准确性,尤其是在单一模态数据存在噪声或不完整的情况下。如图三所示,人工智能驱动的数据融合策略通常分为早期、晚期和中期阶段。
早期融合在输入级别整合了来自所有模态的信息,并将其输入到单一模型中。这些模态可以是原始数据、手工制作或深度特征。联合表示通过向量连接、元素和、元素乘法等操作或双线性池来建立。早期融合简化了设计过程,因为只需训练一个模型。然而,这种方法假设单一模型适合于所有模态。早期融合需要模态之间的一定程度的对齐或同步,尤其在临床设置中,例如,如果模态来自不同的时间点,早期融合可能不适合。早期融合的应用包括集成类似的模式,例如多模态超声图像用于乳腺癌检测或结合CT和/或MRI数据与PET扫描进行癌症检测、治疗计划或生存预测。其他例子包括影像数据与电子病历的融合,例如,整合皮肤镜图像和患者数据用于皮肤病变分类,或宫颈视图和电子病历的融合用于宫颈发育不良诊断。
晚期融合,又称决策级融合,通过为每个模态训练独立模型,再汇总预测结果,实现最终决策。聚合方式包括平均、多数投票、基于贝叶斯的规则或学习模型,如MLP。后期融合允许不同模态使用不同模型架构,适用于异构数据或来自不同时点的模态。即使数据不完整,后期融合也能保留预测能力,通过多数投票处理缺失模态。个体模型误差通常不相关,可降低偏差和方差。在信息密度不均的情况下,主要模态会影响预测,而后期融合可通过设置权重调整每个模态的贡献。例子包括MRI与PSA血液检测、组织学扫描与患者性别融合、基因组学与组织学特征融合等。
中期融合是一种多模态模型策略,其核心思想是将损失传播回每个模态的特征提取层,以在多模态环境中迭代地改进特征表示。相较于早期和晚期融合,中期融合具有更高的灵活性和适用性。它能够在不同的抽象层次上结合不同模式,包括渐进融合和引导融合渐进融合允许将来自高度相关通道的数据在同一水平上结合,迫使模型考虑特定模式之间的相互关联,然后在后续层中与相关性较低的数据进行融合。而引导融合则利用一个模态的信息来指导另一个模态的特征提取,例如,在癌症生存预测中,利用基因组学信息指导组织学特征的选择已被证明是有效的。在多种癌症类型的生存预测中,各种融合类型均有所应用,包括基因组学数据与组织学或乳房X光片图像的结合,以改善生存预测。此外,不同放射学方式的引导融合也用于改善肝脏病变和乳腺组织异常的分割。电子病历还被用于指导从皮肤镜和乳房X光检查图像中提取特征,以提高病变的检测和分类准确性。虽然目前没有确凿的证据表明哪种融合类型在所有情况下都优于其他类型,但各种融合类型都是根据具体数据和任务的特点而设计的,因此在不同场景下都有其适用性和优势。
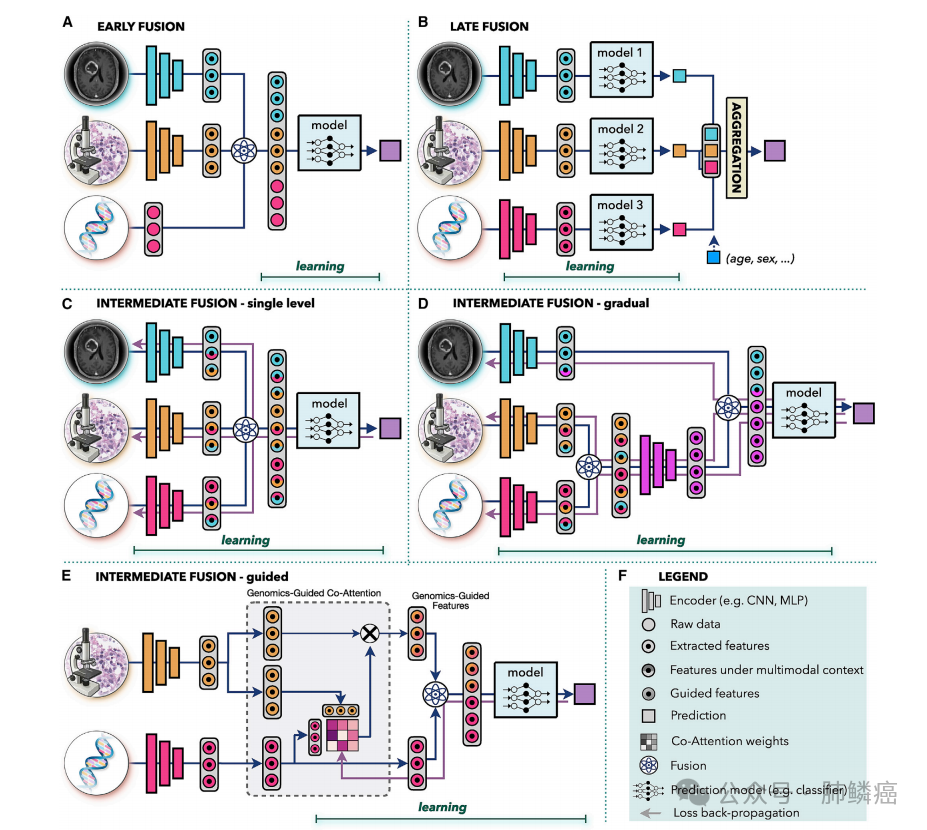 图三:3种多模态数据融合方法
图三:3种多模态数据融合方法
可解释性和模型内省是人工智能开发、部署和验证的一个关键组成部分。由于人工智能模型具有学习抽象特征表示的能力,人们担心这些模型可能会使用虚假的快捷方式预测,而不是学习与临床相关的方面。这种模型在呈现新数据时可能无法推广或歧视某些人群。另一方面,这些模型可以发现新的和临床相关的见解。在这里,我们简要概述了肿瘤学中用于模型自省的不同方法,具体如图四所示,更多的技术细节可以在最近的一篇综述中找到。值得指出的是,这些方法允许我们在进行预测决定时对模型认为重要的部分数据进行反思,但特征表示本身仍然是抽象的。
2.影像学数据可解释性
3.生物分子学数据可解释性
4.多模态数据可解释性
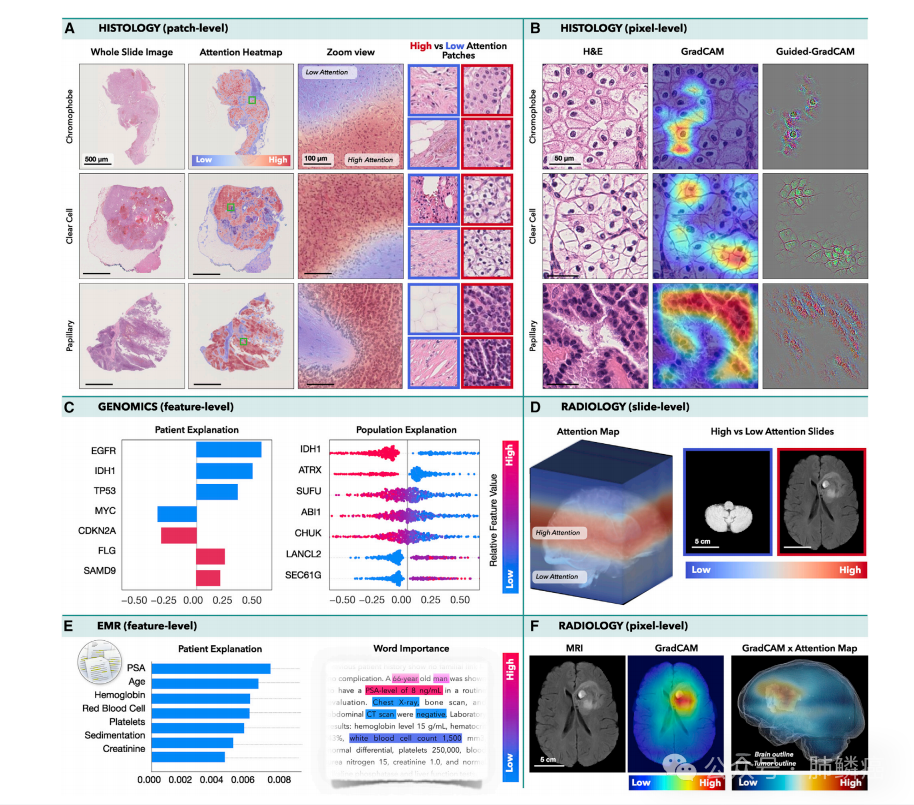
四、多模态数据互作
2.非侵入性替代
3.结果关联
4.早期预测因子
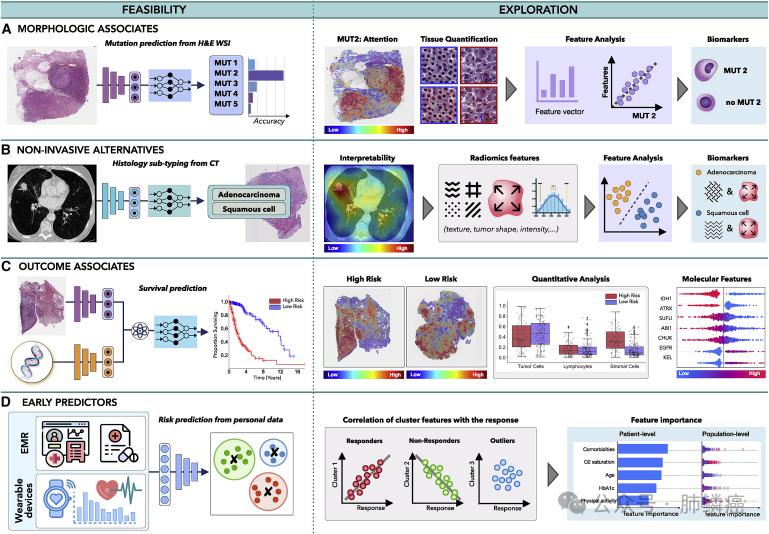
图五:多模态数据互联
医学AI需要大量的数据来训练和部署模型,但现实中常常面临数据缺失的问题。这种挑战不仅限制了模型的性能,还影响了医学决策的准确性和可信度。解决数据缺失主要有两种策略:
A)合成数据生成
通过合成缺失信息来增强数据集,从而弥补数据缺失的不足。合成数据生成技术包括使用已有数据中的信息来填补缺失的数据点,或者利用无监督学习方法如生成对抗网络(GANs)来生成合成数据。然而,合成数据的应用范围受到一定限制,尤其在结果预测和生物标志物探索方面存在挑战。
B)基于Dropout的方法
通过使模型对缺失信息具有鲁棒性来处理不完整的数据。胚胎网络模型是一个典型的例子,它可以在训练和部署过程中处理缺失数据,通过随机选择部分信息并将其组合成单一表示向量来提高模型的鲁棒性。
医学AI需要整合来自不同来源、不同模态和不同规模的数据,这就需要进行有效的数据对齐。本节将深入研究数据对齐的挑战和解决方案:
A)类似模态的对齐
涉及到同一系统的不同成像方式的对齐,通常通过图像配准等技术来实现。然而,面临着解剖结构、变形等挑战,特别是在涉及运动和变形的情况下。
B)不同模态的对齐
跨模态自动编码器等技术能够将来自不同数据源的数据集成和转换,为不同模态数据的对齐提供了一种有效方法。
医学AI技术的透明度和安全性至关重要。本节将讨论通过严格的前瞻性临床试验来验证模型的性能,以确保医学AI技术的有效性和安全性。这些试验能够评估模型在真实世界条件下的表现,促进医生对AI工具的信任和使用。
简评
这篇综述充分描述了人工智能驱动的多模态整合技术在肿瘤学中的强大潜力。具体地,人工智能算法通过充分挖掘各个模态数据内的特征以及各个模态数据间的特征,从而能够更加充分地对肿瘤学进行建模,最终推动精准医疗的发展。同时,该综述还描述了人工智能算法中可解释性和透明性的重要性以及临床实践的各种挑战,以及它们对于推动医学进步的必要性。
——王蕴泽
原文链接:
https://www.sciencedirect.com/science/article/pii/S153561082200441X
点击文末 “阅读原文” 即可查看
参考文献
Lipkova J, Chen R J, Chen B, et al. Artificial intelligence for multimodal data integration in oncology[J]. Cancer cell, 2022, 40(10): 1095-1110.
专栏 · 推荐
肺鳞癌 | 肿瘤微生物系列
关于我们
ABOUT US
本公众号由浙江大学国际校区ZJE-刘坚课题组创办,聚焦于肺鳞癌分子作用机制,关注并发布最新肺鳞癌领域前沿进展,包括诊断、靶向治疗,旨在打造一个良好的肺鳞癌科研共享平台。请关注我们的肺癌三维基因组多组学网站(http://www.lungcancer3d.net/)。
扫描二维码
立即关注
微信号 : LUSC_2021-






评论前必须登录!
立即登录 注册