为了训练这款敦煌OCR引擎,研究院与方老师团队合作挑选了5000张具有代表性的敦煌图片,包括4600张楷书,400张草书和行书(以草书为主),之后与金连文老师团队合作进行了敦煌数据标注工作。
敦煌文献大部分是手写体,还包括部分的草书和行书,版式也不规范。相比雕版古籍而言,它的标注工作要复杂很多。为了规范、有效地开展敦煌数据标注工作,研究院专门成立了敦煌数据标注项目组,由校对部副部长王金雷任项目经理,以研究院的人工智能OCR技术和如是古籍数字化生产平台为依托,从社会上招募了一批专职校对员进行标注。
数据标注主要包括切分标注和文字标注。切分标注从2021年12月16日启动,至2022年2月16日完成切分校对、审定,历时2个月,参与人数达23人。
文字标注要复杂很多。敦煌古籍中异体字的现象很普遍,“今”字常常写作“𫝆”,“若”字常常写作“𠰥”,虽然字形非常相似,但仍属于不同的计算机文字。我们采用通字校对的原则进行校对(即采用与图片字最接近的计算机文字进行校对,如:今与𫝆作为两个不同的字),就需要把它们区分开来。另外,400页的草书和行书,还需要找懂得书法的专门人才进行校对,因此文字标注也分成了楷书和行草书两个小组分开进行。楷书文字标注从2022年2月23启动,至6月20日完成文字校对、审定,历时近4个月,参与人数达28人。行草书文字标注从4月8日启动,至7月7日完成文字校对、审定,历时近3个月,共4人参与。
 ai论文写作
ai论文写作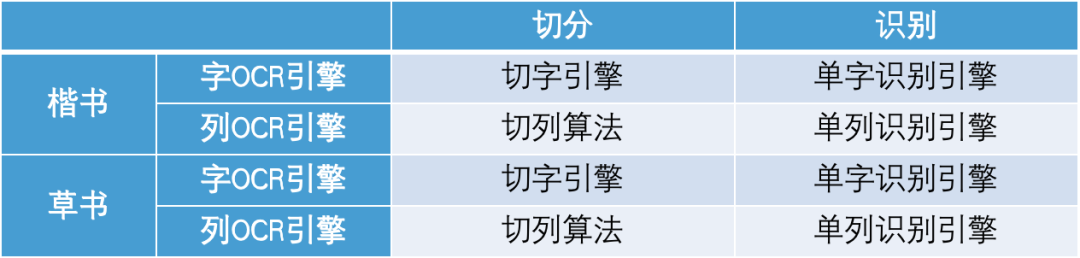














评论前必须登录!
立即登录 注册